The first obstacle wasn't schema design or LangChain wiring. It was a 2010 PDF where PyPDF scatters blip numbers across the page as floating coordinates because the radar diagram breaks text extraction. You get back a list of integers and names with no reliable connection between them.
I built this to index all 34 editions of the Thoughtworks Technology Radar, from Vol. 1 (January 2010) through Vol. 34 (2026), into a GraphRAG system built on Neo4j and Qdrant. The goal was a chat interface that could answer questions like "what practices should I consider for building an AI customer support agent?" by pulling on 15 years of Thoughtworks technology recommendations. The stack: Python 3.13, LangChain, Neo4j 5.26, Qdrant v1.18, Docker Compose for local infrastructure, and either OpenAI (gpt-4o) or a local Ollama instance (llama3.1:8b) for LLM inference, switchable via a single environment variable.
This is a technical account of building that. The AI parts were not the hard parts.
Why a knowledge graph?
Plain RAG (formalised in the 2020 Lewis et al. paper) chunks documents, embeds those chunks, and at query time finds the nearest neighbors to the embedded question. That approach handles "what is continuous delivery?" well. It handles "which Adopt-ring tools warn about observability gaps?" poorly, because cosine similarity has no concept of ring membership, relationship types, or multi-hop traversal. You can ask the question, and the vector store returns chunks that mention rings and observability, but it cannot reason about the structural connection between them.
A knowledge graph adds a structured layer. Nodes represent entities; typed edges represent relationships between them. In Neo4j, node types are called labels (Blip, Ring, Quadrant, Theme, etc.) and attributes are properties (name, ring, shortSummary). Relationships also have types (IN_RING, COMPLEMENTS, BUILT_ON) and can carry properties. The schema of allowed node and relationship types is called an ontology; the hierarchical organization of those types is the taxonomy.
Microsoft's 2024 GraphRAG paper takes this idea further, using LLMs to auto-generate community summaries over the graph for global sensemaking queries across millions of tokens. My use case is narrower: structured traversal over a known, finite domain. The core intuition is the same. For this project the ontology is small and well-understood: eight node types and twelve relationship types. That is deliberate. I am not building a general-purpose knowledge base. The queries I need are specific: "which blips in Adopt complement a practice tagged observability?" and "which blips integrate with Kubernetes, and at what ring?" Those are finite, predictable graph traversals. I looked at RDF/SPARQL briefly and decided the formal ontology machinery was a mismatch for a practical ML engineering project. Neo4j with Cypher, APOC, and the GenAI plugin suited the problem.
There are other approaches to hybrid RAG. I wrote about a multi-agent RAG system that uses BM25 hybrid search with ChromaDB for a different use case (debugging knowledge and incident memory). That approach is simpler to set up and works well when you don't need to traverse typed relationships. The knowledge graph approach requires more engineering but pays off when entity relationships are central to the queries you want to answer, which in the Tech Radar domain they often are.
Fifteen years of PDF chaos
The Thoughtworks Technology Radar has been published since January 2010. Across 34 editions the PDF layout changed substantially three times, and each layout requires its own parsing strategy.
Format detection is deterministic; no LLM is involved. The parser counts two signals from the extracted text.
A modern-format signal: occurrences of a numbered item (e.g., 17. Canary releases) followed, within two non-empty lines, by a ring value (Adopt, Trial, Assess, or Hold). Five or more such matches means modern format. Modern editions (Vol. 11+, 2014 onward) are cleanly structured with numbered blip sections and the ring value on the next line.
An intermediate-format signal: standalone ring-value lines that are not immediately adjacent to another ring value. The adjacency check is necessary because early editions embed ring names inside the radar diagram image, which PyPDF extracts as a cluster of adjacent ring-name tokens (Adopt Trial Assess Hold all on the same line). An intermediate edition (Vol. 5–10, 2011–2013) uses ring names as section headers with all blips in that ring grouped beneath.
If neither signal fires, the PDF is classified as early format.
%3btext-align:center%3b%7d%23mermaid-0 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%239370DB%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:%239370DB%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%239370DB%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M250.305%2c47.5L250.221%2c51.583C250.138%2c55.667%2c249.971%2c63.833%2c249.888%2c71.417C249.805%2c79%2c249.805%2c86%2c249.805%2c89.5L249.805%2c93' id='mermaid-0-L_START_C1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_START_C1_0' data-points='W3sieCI6MjUwLjMwNDY4NzUsInkiOjQ3LjV9LHsieCI6MjQ5LjgwNDY4NzUsInkiOjcyfSx7IngiOjI0OS44MDQ2ODc1LCJ5Ijo5N31d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M191.727%2c312.563L180.04%2c328.409C168.352%2c344.256%2c144.977%2c375.948%2c133.289%2c404.262C121.602%2c432.576%2c121.602%2c457.51%2c121.602%2c469.978L121.602%2c482.445' id='mermaid-0-L_C1_MOD_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C1_MOD_0' data-points='W3sieCI6MTkxLjcyNzEwMzI4NjEwNDE1LCJ5IjozMTIuNTYzMDQwNzg2MTA0MX0seyJ4IjoxMjEuNjAxNTYyNSwieSI6NDA3LjY0MDYyNX0seyJ4IjoxMjEuNjAxNTYyNSwieSI6NDg2LjQ0NTMxMjV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M307.882%2c312.563L319.57%2c328.409C331.257%2c344.256%2c354.633%2c375.948%2c366.32%2c397.294C378.008%2c418.641%2c378.008%2c429.641%2c378.008%2c435.141L378.008%2c440.641' id='mermaid-0-L_C1_C2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C1_C2_0' data-points='W3sieCI6MzA3Ljg4MjI3MTcxMzg5NTksInkiOjMxMi41NjMwNDA3ODYxMDQxfSx7IngiOjM3OC4wMDc4MTI1LCJ5Ijo0MDcuNjQwNjI1fSx7IngiOjM3OC4wMDc4MTI1LCJ5Ijo0NDQuNjQwNjI1fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M331.123%2c583.365L316.848%2c597.346C302.573%2c611.326%2c274.023%2c639.288%2c259.748%2c660.769C245.473%2c682.25%2c245.473%2c697.25%2c245.473%2c704.75L245.473%2c712.25' id='mermaid-0-L_C2_INT_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C2_INT_0' data-points='W3sieCI6MzMxLjEyMjUwNjg0OTQxNzA1LCJ5Ijo1ODMuMzY0Njk0MzQ5NDE3fSx7IngiOjI0NS40NzI2NTYyNSwieSI6NjY3LjI1fSx7IngiOjI0NS40NzI2NTYyNSwieSI6NzE2LjI1fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M424.893%2c583.365L439.168%2c597.346C453.443%2c611.326%2c481.993%2c639.288%2c496.268%2c658.769C510.543%2c678.25%2c510.543%2c689.25%2c510.543%2c694.75L510.543%2c700.25' id='mermaid-0-L_C2_EAR_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C2_EAR_0' data-points='W3sieCI6NDI0Ljg5MzExODE1MDU4Mjk1LCJ5Ijo1ODMuMzY0Njk0MzQ5NDE3fSx7IngiOjUxMC41NDI5Njg3NSwieSI6NjY3LjI1fSx7IngiOjUxMC41NDI5Njg3NSwieSI6NzA0LjI1fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_START_C1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(121.6015625%2c 407.640625)'%3e%3cg class='label' data-id='L_C1_MOD_0' transform='translate(-66.6953125%2c -12)'%3e%3cforeignObject width='133.390625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3e5 or more matches%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(378.0078125%2c 407.640625)'%3e%3cg class='label' data-id='L_C1_C2_0' transform='translate(-44.03125%2c -12)'%3e%3cforeignObject width='88.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3efewer than 5%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(245.47265625%2c 667.25)'%3e%3cg class='label' data-id='L_C2_INT_0' transform='translate(-64.03125%2c -12)'%3e%3cforeignObject width='128.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3e4 or more isolated%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(510.54296875%2c 667.25)'%3e%3cg class='label' data-id='L_C2_EAR_0' transform='translate(-44.03125%2c -12)'%3e%3cforeignObject width='88.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3efewer than 4%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-START-0' data-look='classic' transform='translate(249.8046875%2c 27.5)'%3e%3cg class='basic label-container outer-path'%3e%3cpath d='M-59.125 -19.5 C-18.930738000301233 -19.5%2c 21.263523999397535 -19.5%2c 59.125 -19.5 C59.125 -19.5%2c 59.125 -19.5%2c 59.125 -19.5 C59.441086436555004 -19.489863723204607%2c 59.75717287311 -19.479727446409214%2c 60.3743692896239 -19.45993515863156 C60.72289673400997 -19.426313135237212%2c 61.07142417839604 -19.392691111842865%2c 61.618604652847864 -19.3399052695533 C62.05751021678305 -19.26894642173974%2c 62.49641578071824 -19.197987573926188%2c 62.85259325967676 -19.140403561325776 C63.275950412172165 -19.043775053932304%2c 63.69930756466758 -18.94714654653883%2c 64.07126438623538 -18.862249829261074 C64.54244324909214 -18.72240641603351%2c 65.01362211194889 -18.58256300280595%2c 65.2696102514606 -18.50658706670804 C65.5498841759091 -18.40344367168724%2c 65.8301581003576 -18.300300276666434%2c 66.4427065951478 -18.074876768247425 C66.81431976190909 -17.910374642835126%2c 67.18593292867038 -17.74587251742283%2c 67.58573291279238 -17.568892924097174 C68.01249393137572 -17.346251974055725%2c 68.43925494995906 -17.123611024014277%2c 68.69399226407678 -16.990714730406097 C68.99557252770212 -16.80789500231407%2c 69.29715279132746 -16.625075274222038%2c 69.7629305736057 -16.342718045390892 C70.12504573677313 -16.09012218327806%2c 70.48716089994056 -15.837526321165228%2c 70.78815534457871 -15.627565626425154 C71.0257431364338 -15.43809568489738%2c 71.26333092828891 -15.248625743369608%2c 71.76545370850187 -14.848196188198123 C71.96755306690014 -14.664654898156817%2c 72.16965242529841 -14.48111360811551%2c 72.69080973676799 -14.007812326905688 C72.87065901387457 -13.822103182392874%2c 73.05050829098117 -13.636394037880061%2c 73.56042094296865 -13.10986736009568 C73.88235368299362 -12.731706845170496%2c 74.2042864230186 -12.35354633024531%2c 74.37071390812658 -12.158051136245305 C74.65633946343921 -11.775338913149776%2c 74.94196501875183 -11.392626690054248%2c 75.11835896464063 -11.156274872382312 C75.37469416107758 -10.762475175017023%2c 75.63102935751452 -10.368675477651735%2c 75.80028387860425 -10.108655082055241 C75.99045084112511 -9.770994383606386%2c 76.18061780364599 -9.433333685157528%2c 76.4136864742735 -9.019496659696287 C76.56874474286333 -8.697514847254054%2c 76.72380301145316 -8.37553303481182%2c 76.95604614880834 -7.893275190886684 C77.08977842248237 -7.562953889374219%2c 77.2235106961564 -7.232632587861754%2c 77.42513422997033 -6.734618561215508 C77.53503548590648 -6.403613488722987%2c 77.64493674184264 -6.072608416230467%2c 77.81902313421489 -5.548287939305138 C77.9144643450867 -5.184329237768489%2c 78.0099055559585 -4.82037053623184%2c 78.13609428754556 -4.339158212148133 C78.22694953635983 -3.872635711750492%2c 78.3178047851741 -3.406113211352851%2c 78.37504477658177 -3.1121979531509023 C78.41495181351016 -2.8026868552701525%2c 78.45485885043854 -2.4931757573894027%2c 78.53489270250937 -1.872449005199798 C78.56397697298706 -1.4194380161090945%2c 78.59306124346476 -0.966427027018391%2c 78.61498121591342 -0.6250057626472757 C78.61498121591342 -0.24915752268659647%2c 78.61498121591342 0.12669071727408276%2c 78.61498121591342 0.625005762647271 C78.59774092350209 0.8935372330673925%2c 78.58050063109074 1.1620687034875141%2c 78.53489270250937 1.8724490051997846 C78.49079977158978 2.214425070278046%2c 78.44670684067019 2.5564011353563076%2c 78.37504477658177 3.1121979531508885 C78.30396827295297 3.4771607772604005%2c 78.23289176932418 3.842123601369913%2c 78.13609428754556 4.339158212148129 C78.0531196406397 4.655576502239651%2c 77.97014499373383 4.971994792331172%2c 77.81902313421489 5.548287939305125 C77.69452780313867 5.923248040869421%2c 77.57003247206245 6.298208142433717%2c 77.42513422997033 6.734618561215495 C77.26741792654276 7.1241808799188675%2c 77.1097016231152 7.51374319862224%2c 76.95604614880834 7.893275190886679 C76.75303135578501 8.314839752420314%2c 76.5500165627617 8.73640431395395%2c 76.4136864742735 9.019496659696284 C76.25480102689343 9.301613860415763%2c 76.09591557951336 9.583731061135245%2c 75.80028387860425 10.108655082055236 C75.59509655891586 10.423877905606757%2c 75.38990923922745 10.739100729158276%2c 75.11835896464065 11.156274872382301 C74.84746434450416 11.519248984357603%2c 74.57656972436767 11.882223096332904%2c 74.37071390812659 12.158051136245302 C74.16079087303201 12.404638678226467%2c 73.95086783793745 12.651226220207635%2c 73.56042094296866 13.10986736009567 C73.24976453973964 13.430645601794668%2c 72.93910813651063 13.751423843493665%2c 72.69080973676799 14.007812326905684 C72.42456751393678 14.249606469297794%2c 72.15832529110557 14.491400611689901%2c 71.7654537085019 14.848196188198111 C71.47194792822435 15.082259237452613%2c 71.17844214794681 15.316322286707114%2c 70.78815534457871 15.627565626425152 C70.45391005264524 15.860720672832457%2c 70.11966476071177 16.09387571923976%2c 69.7629305736057 16.34271804539089 C69.47109312311143 16.519631622907742%2c 69.17925567261716 16.696545200424595%2c 68.69399226407678 16.990714730406093 C68.36579451977452 17.16193528338789%2c 68.03759677547228 17.333155836369688%2c 67.58573291279238 17.56889292409717 C67.1390317254657 17.766634288806777%2c 66.69233053813902 17.964375653516385%2c 66.4427065951478 18.07487676824742 C66.13488251431737 18.18815887548763%2c 65.82705843348694 18.30144098272784%2c 65.26961025146062 18.506587066708033 C64.820228604235 18.639961180752195%2c 64.37084695700938 18.77333529479636%2c 64.07126438623541 18.86224982926107 C63.61534012620172 18.966311566429916%2c 63.15941586616803 19.070373303598764%2c 62.852593259676766 19.140403561325773 C62.37232837410386 19.218049063515387%2c 61.89206348853095 19.295694565705002%2c 61.61860465284788 19.3399052695533 C61.28237257851505 19.372341173385955%2c 60.946140504182225 19.40477707721861%2c 60.3743692896239 19.45993515863156 C60.07246107490805 19.469616767448805%2c 59.770552860192204 19.47929837626605%2c 59.12500000000001 19.5 C59.12500000000001 19.5%2c 59.125 19.5%2c 59.125 19.5 C27.636397644808234 19.5%2c -3.852204710383532 19.5%2c -59.12499999999999 19.5 C-59.60526904469045 19.484598706523762%2c -60.08553808938092 19.469197413047524%2c -60.37436928962389 19.45993515863156 C-60.77419902779181 19.421364064656114%2c -61.174028765959726 19.38279297068067%2c -61.61860465284787 19.3399052695533 C-61.87555930261459 19.298362834492085%2c -62.1325139523813 19.25682039943087%2c -62.85259325967676 19.140403561325773 C-63.110757008289134 19.0814793703809%2c -63.3689207569015 19.022555179436026%2c -64.07126438623538 18.862249829261074 C-64.48647038662877 18.739018867805093%2c -64.90167638702214 18.61578790634911%2c -65.26961025146059 18.506587066708043 C-65.64558656464672 18.36822430796861%2c -66.02156287783285 18.229861549229174%2c -66.4427065951478 18.074876768247425 C-66.76204982817369 17.933512991967298%2c -67.08139306119958 17.792149215687168%2c -67.58573291279238 17.568892924097174 C-67.9656375775878 17.37069690381396%2c -68.3455422423832 17.172500883530745%2c -68.69399226407678 16.990714730406097 C-68.91936286634308 16.8540937468876%2c -69.14473346860937 16.7174727633691%2c -69.76293057360569 16.3427180453909 C-70.04775683239863 16.144035577186962%2c -70.33258309119157 15.945353108983028%2c -70.78815534457871 15.627565626425156 C-71.05141128725153 15.417626017678437%2c -71.31466722992434 15.207686408931716%2c -71.76545370850187 14.848196188198125 C-72.12196019888282 14.524426426278993%2c -72.47846668926375 14.200656664359858%2c -72.69080973676797 14.007812326905697 C-72.907112735803 13.784461721595546%2c -73.12341573483802 13.561111116285396%2c -73.56042094296865 13.109867360095677 C-73.80508567017593 12.822470249700643%2c -74.0497503973832 12.53507313930561%2c -74.37071390812658 12.158051136245307 C-74.65498671726222 11.777151469789219%2c -74.93925952639788 11.396251803333133%2c -75.11835896464063 11.156274872382316 C-75.33547223506636 10.822730585932096%2c -75.55258550549208 10.489186299481878%2c -75.80028387860425 10.108655082055249 C-76.01788185948742 9.722287832812311%2c -76.23547984037059 9.335920583569376%2c -76.4136864742735 9.019496659696289 C-76.54889916245205 8.738724619605472%2c -76.6841118506306 8.457952579514654%2c -76.95604614880834 7.893275190886686 C-77.10071190306026 7.535947980962376%2c -77.24537765731216 7.178620771038068%2c -77.42513422997033 6.73461856121551 C-77.54108442715187 6.385395041459755%2c -77.65703462433343 6.0361715217039995%2c -77.81902313421489 5.5482879393051325 C-77.92440807659445 5.146409479888947%2c -78.02979301897399 4.74453102047276%2c -78.13609428754556 4.339158212148136 C-78.21456966949013 3.936203711640627%2c -78.29304505143469 3.5332492111331186%2c -78.37504477658177 3.112197953150904 C-78.42752695859332 2.705156513248435%2c -78.48000914060486 2.298115073345966%2c -78.53489270250937 1.872449005199809 C-78.55166154700638 1.6112607165912798%2c -78.56843039150338 1.3500724279827503%2c -78.61498121591342 0.6250057626472781 C-78.61498121591342 0.2937696511980111%2c -78.61498121591342 -0.037466460251255995%2c -78.61498121591342 -0.6250057626472687 C-78.59222580907749 -0.9794395919507052%2c -78.56947040224155 -1.3338734212541417%2c -78.53489270250937 -1.8724490051997822 C-78.4835257211958 -2.2708411687100174%2c -78.43215873988224 -2.669233332220253%2c -78.37504477658177 -3.112197953150895 C-78.31833195336104 -3.403406314129953%2c -78.2616191301403 -3.694614675109011%2c -78.13609428754556 -4.339158212148126 C-78.05093091985242 -4.663923043199143%2c -77.96576755215926 -4.98868787425016%2c -77.81902313421489 -5.548287939305123 C-77.73077106778837 -5.814089102324532%2c -77.64251900136185 -6.07989026534394%2c -77.42513422997033 -6.734618561215485 C-77.26364718315479 -7.1334946889895114%2c -77.10216013633925 -7.532370816763537%2c -76.95604614880834 -7.893275190886676 C-76.79068606130805 -8.236648950720115%2c -76.62532597380775 -8.580022710553553%2c -76.4136864742735 -9.019496659696282 C-76.25512609235736 -9.301036673768122%2c -76.09656571044121 -9.582576687839962%2c -75.80028387860425 -10.108655082055243 C-75.60670549984177 -10.406043454907437%2c -75.41312712107927 -10.703431827759628%2c -75.11835896464063 -11.156274872382308 C-74.91724853423995 -11.42574452758211%2c -74.71613810383927 -11.695214182781912%2c -74.37071390812659 -12.158051136245302 C-74.17219202035471 -12.391246241837562%2c -73.97367013258285 -12.624441347429823%2c -73.56042094296866 -13.10986736009567 C-73.26175624300157 -13.418263183639581%2c -72.96309154303448 -13.726659007183494%2c -72.69080973676799 -14.007812326905677 C-72.37471359585723 -14.294882478635252%2c -72.05861745494646 -14.581952630364826%2c -71.7654537085019 -14.848196188198107 C-71.56241215408916 -15.010116424679584%2c -71.35937059967642 -15.17203666116106%2c -70.78815534457871 -15.627565626425149 C-70.5168319005126 -15.816829115603081%2c -70.24550845644649 -16.006092604781013%2c -69.76293057360571 -16.342718045390885 C-69.51562276269846 -16.492637493704876%2c -69.26831495179121 -16.642556942018867%2c -68.69399226407678 -16.99071473040609 C-68.42286120751706 -17.132163628945573%2c -68.15173015095733 -17.273612527485053%2c -67.5857329127924 -17.56889292409717 C-67.2413192101455 -17.721354653589458%2c -66.89690550749862 -17.87381638308175%2c -66.44270659514781 -18.07487676824742 C-66.08505545906284 -18.206495692417548%2c -65.72740432297788 -18.338114616587674%2c -65.26961025146062 -18.506587066708033 C-64.87155748500803 -18.624727038369553%2c -64.47350471855543 -18.742867010031077%2c -64.07126438623541 -18.862249829261067 C-63.664355693588554 -18.95512408303034%2c -63.25744700094169 -19.047998336799616%2c -62.852593259676766 -19.140403561325773 C-62.400642604136756 -19.213471438383802%2c -61.94869194859675 -19.286539315441832%2c -61.61860465284788 -19.3399052695533 C-61.322119937257305 -19.36850679349128%2c -61.02563522166673 -19.397108317429264%2c -60.3743692896239 -19.45993515863156 C-59.93791749185066 -19.473931318284258%2c -59.501465694077424 -19.487927477936957%2c -59.12500000000001 -19.5 C-59.12500000000001 -19.5%2c -59.12500000000001 -19.5%2c -59.125 -19.5' stroke='none' stroke-width='0' fill='%23ECECFF' style=''/%3e%3cpath d='M-59.125 -19.5 C-14.14300636837202 -19.5%2c 30.83898726325596 -19.5%2c 59.125 -19.5 M-59.125 -19.5 C-23.099267883493 -19.5%2c 12.926464233014002 -19.5%2c 59.125 -19.5 M59.125 -19.5 C59.125 -19.5%2c 59.125 -19.5%2c 59.125 -19.5 M59.125 -19.5 C59.125 -19.5%2c 59.125 -19.5%2c 59.125 -19.5 M59.125 -19.5 C59.376235987692546 -19.491943350875886%2c 59.62747197538509 -19.483886701751768%2c 60.3743692896239 -19.45993515863156 M59.125 -19.5 C59.56731427011552 -19.485815842269893%2c 60.009628540231034 -19.471631684539787%2c 60.3743692896239 -19.45993515863156 M60.3743692896239 -19.45993515863156 C60.6993426635471 -19.42858536808685%2c 61.0243160374703 -19.397235577542144%2c 61.618604652847864 -19.3399052695533 M60.3743692896239 -19.45993515863156 C60.745002340138264 -19.424180633999896%2c 61.11563539065263 -19.388426109368236%2c 61.618604652847864 -19.3399052695533 M61.618604652847864 -19.3399052695533 C61.931637094763936 -19.289296611947155%2c 62.24466953668 -19.238687954341007%2c 62.85259325967676 -19.140403561325776 M61.618604652847864 -19.3399052695533 C62.07625124821462 -19.265916517116757%2c 62.53389784358137 -19.191927764680216%2c 62.85259325967676 -19.140403561325776 M62.85259325967676 -19.140403561325776 C63.14453556113062 -19.073769636120492%2c 63.436477862584475 -19.007135710915204%2c 64.07126438623538 -18.862249829261074 M62.85259325967676 -19.140403561325776 C63.28171967886686 -19.042458256457223%2c 63.710846098056955 -18.94451295158867%2c 64.07126438623538 -18.862249829261074 M64.07126438623538 -18.862249829261074 C64.4293785544107 -18.755963423926268%2c 64.78749272258602 -18.649677018591465%2c 65.2696102514606 -18.50658706670804 M64.07126438623538 -18.862249829261074 C64.47265183755648 -18.743120140634698%2c 64.87403928887758 -18.623990452008325%2c 65.2696102514606 -18.50658706670804 M65.2696102514606 -18.50658706670804 C65.69936213973746 -18.34843439923925%2c 66.12911402801433 -18.190281731770455%2c 66.4427065951478 -18.074876768247425 M65.2696102514606 -18.50658706670804 C65.53894440041269 -18.40746961019609%2c 65.80827854936477 -18.308352153684144%2c 66.4427065951478 -18.074876768247425 M66.4427065951478 -18.074876768247425 C66.72853642707983 -17.948348380491826%2c 67.01436625901187 -17.821819992736224%2c 67.58573291279238 -17.568892924097174 M66.4427065951478 -18.074876768247425 C66.81774936375375 -17.908856459834023%2c 67.19279213235968 -17.742836151420622%2c 67.58573291279238 -17.568892924097174 M67.58573291279238 -17.568892924097174 C67.8235288543672 -17.444834933693166%2c 68.061324795942 -17.320776943289157%2c 68.69399226407678 -16.990714730406097 M67.58573291279238 -17.568892924097174 C67.91041774079258 -17.399505057300026%2c 68.2351025687928 -17.230117190502877%2c 68.69399226407678 -16.990714730406097 M68.69399226407678 -16.990714730406097 C69.04482576855347 -16.77803739826581%2c 69.39565927303016 -16.565360066125518%2c 69.7629305736057 -16.342718045390892 M68.69399226407678 -16.990714730406097 C69.08176867466234 -16.755642391482%2c 69.4695450852479 -16.520570052557897%2c 69.7629305736057 -16.342718045390892 M69.7629305736057 -16.342718045390892 C70.16504538245435 -16.06222016200759%2c 70.567160191303 -15.78172227862429%2c 70.78815534457871 -15.627565626425154 M69.7629305736057 -16.342718045390892 C70.1187864014688 -16.094488424624103%2c 70.47464222933189 -15.846258803857316%2c 70.78815534457871 -15.627565626425154 M70.78815534457871 -15.627565626425154 C71.16069689435373 -15.330473654226566%2c 71.53323844412876 -15.033381682027978%2c 71.76545370850187 -14.848196188198123 M70.78815534457871 -15.627565626425154 C71.14004612995281 -15.346942089296384%2c 71.4919369153269 -15.066318552167612%2c 71.76545370850187 -14.848196188198123 M71.76545370850187 -14.848196188198123 C72.08308020109386 -14.559736211562551%2c 72.40070669368585 -14.27127623492698%2c 72.69080973676799 -14.007812326905688 M71.76545370850187 -14.848196188198123 C72.11416877074035 -14.531502395168081%2c 72.46288383297885 -14.214808602138037%2c 72.69080973676799 -14.007812326905688 M72.69080973676799 -14.007812326905688 C73.0305034974441 -13.657050629631174%2c 73.37019725812021 -13.30628893235666%2c 73.56042094296865 -13.10986736009568 M72.69080973676799 -14.007812326905688 C72.8744748768671 -13.818162990564922%2c 73.0581400169662 -13.628513654224157%2c 73.56042094296865 -13.10986736009568 M73.56042094296865 -13.10986736009568 C73.84434824202721 -12.776350198700495%2c 74.12827554108578 -12.442833037305308%2c 74.37071390812658 -12.158051136245305 M73.56042094296865 -13.10986736009568 C73.824554006422 -12.799601634166292%2c 74.08868706987535 -12.489335908236905%2c 74.37071390812658 -12.158051136245305 M74.37071390812658 -12.158051136245305 C74.63250768427557 -11.807271326109301%2c 74.89430146042456 -11.456491515973296%2c 75.11835896464063 -11.156274872382312 M74.37071390812658 -12.158051136245305 C74.60514433073239 -11.843935727004373%2c 74.8395747533382 -11.52982031776344%2c 75.11835896464063 -11.156274872382312 M75.11835896464063 -11.156274872382312 C75.34774959160542 -10.803869269356241%2c 75.57714021857021 -10.45146366633017%2c 75.80028387860425 -10.108655082055241 M75.11835896464063 -11.156274872382312 C75.3272846231725 -10.835308956482686%2c 75.53621028170437 -10.51434304058306%2c 75.80028387860425 -10.108655082055241 M75.80028387860425 -10.108655082055241 C76.01815795652362 -9.721797594566677%2c 76.23603203444299 -9.334940107078113%2c 76.4136864742735 -9.019496659696287 M75.80028387860425 -10.108655082055241 C76.04477508222325 -9.674536192610718%2c 76.28926628584227 -9.240417303166195%2c 76.4136864742735 -9.019496659696287 M76.4136864742735 -9.019496659696287 C76.55818656071918 -8.71943913838529%2c 76.70268664716485 -8.419381617074292%2c 76.95604614880834 -7.893275190886684 M76.4136864742735 -9.019496659696287 C76.58366400654546 -8.666534676997006%2c 76.75364153881742 -8.313572694297726%2c 76.95604614880834 -7.893275190886684 M76.95604614880834 -7.893275190886684 C77.10807576561156 -7.517759098090064%2c 77.26010538241476 -7.142243005293444%2c 77.42513422997033 -6.734618561215508 M76.95604614880834 -7.893275190886684 C77.14277459795561 -7.432052311343971%2c 77.32950304710288 -6.970829431801256%2c 77.42513422997033 -6.734618561215508 M77.42513422997033 -6.734618561215508 C77.53661625976864 -6.398852449712295%2c 77.64809828956695 -6.063086338209082%2c 77.81902313421489 -5.548287939305138 M77.42513422997033 -6.734618561215508 C77.5716009741112 -6.293484064169745%2c 77.71806771825207 -5.852349567123982%2c 77.81902313421489 -5.548287939305138 M77.81902313421489 -5.548287939305138 C77.88883977200489 -5.28204684068965%2c 77.95865640979488 -5.015805742074161%2c 78.13609428754556 -4.339158212148133 M77.81902313421489 -5.548287939305138 C77.92745431688465 -5.134792845413509%2c 78.0358854995544 -4.721297751521881%2c 78.13609428754556 -4.339158212148133 M78.13609428754556 -4.339158212148133 C78.21034034809531 -3.9579203831355962%2c 78.28458640864507 -3.5766825541230594%2c 78.37504477658177 -3.1121979531509023 M78.13609428754556 -4.339158212148133 C78.19702320759403 -4.02630108503107%2c 78.2579521276425 -3.713443957914008%2c 78.37504477658177 -3.1121979531509023 M78.37504477658177 -3.1121979531509023 C78.43043657703856 -2.682590087156237%2c 78.48582837749537 -2.2529822211615724%2c 78.53489270250937 -1.872449005199798 M78.37504477658177 -3.1121979531509023 C78.42804433529639 -2.7011438417069544%2c 78.48104389401102 -2.290089730263006%2c 78.53489270250937 -1.872449005199798 M78.53489270250937 -1.872449005199798 C78.56332422951704 -1.4296050225397503%2c 78.59175575652472 -0.9867610398797025%2c 78.61498121591342 -0.6250057626472757 M78.53489270250937 -1.872449005199798 C78.5563511823157 -1.5382158612430863%2c 78.57780966212202 -1.2039827172863748%2c 78.61498121591342 -0.6250057626472757 M78.61498121591342 -0.6250057626472757 C78.61498121591342 -0.34055149669279905%2c 78.61498121591342 -0.0560972307383224%2c 78.61498121591342 0.625005762647271 M78.61498121591342 -0.6250057626472757 C78.61498121591342 -0.3144817452903152%2c 78.61498121591342 -0.003957727933354693%2c 78.61498121591342 0.625005762647271 M78.61498121591342 0.625005762647271 C78.5880220145667 1.0449170846979026%2c 78.56106281322 1.4648284067485342%2c 78.53489270250937 1.8724490051997846 M78.61498121591342 0.625005762647271 C78.59590546253757 0.9221260191469461%2c 78.57682970916174 1.2192462756466211%2c 78.53489270250937 1.8724490051997846 M78.53489270250937 1.8724490051997846 C78.49575709870133 2.1759770201358184%2c 78.4566214948933 2.4795050350718517%2c 78.37504477658177 3.1121979531508885 M78.53489270250937 1.8724490051997846 C78.47680823463439 2.322940667962577%2c 78.41872376675941 2.7734323307253685%2c 78.37504477658177 3.1121979531508885 M78.37504477658177 3.1121979531508885 C78.29503744721487 3.5230186798949523%2c 78.21503011784795 3.933839406639016%2c 78.13609428754556 4.339158212148129 M78.37504477658177 3.1121979531508885 C78.29121600637573 3.542640970942063%2c 78.2073872361697 3.9730839887332383%2c 78.13609428754556 4.339158212148129 M78.13609428754556 4.339158212148129 C78.0486905695925 4.67246646971415%2c 77.96128685163943 5.005774727280172%2c 77.81902313421489 5.548287939305125 M78.13609428754556 4.339158212148129 C78.06920903436837 4.594220670764855%2c 78.00232378119118 4.849283129381583%2c 77.81902313421489 5.548287939305125 M77.81902313421489 5.548287939305125 C77.706588147629 5.886924204819463%2c 77.59415316104312 6.225560470333801%2c 77.42513422997033 6.734618561215495 M77.81902313421489 5.548287939305125 C77.68205924385569 5.960801354834592%2c 77.5450953534965 6.373314770364059%2c 77.42513422997033 6.734618561215495 M77.42513422997033 6.734618561215495 C77.30663385201099 7.027316785824002%2c 77.18813347405165 7.320015010432509%2c 76.95604614880834 7.893275190886679 M77.42513422997033 6.734618561215495 C77.24128086290976 7.188739932418139%2c 77.05742749584918 7.642861303620783%2c 76.95604614880834 7.893275190886679 M76.95604614880834 7.893275190886679 C76.79985511640544 8.21760921162403%2c 76.64366408400254 8.54194323236138%2c 76.4136864742735 9.019496659696284 M76.95604614880834 7.893275190886679 C76.78220669410794 8.25425653814053%2c 76.60836723940754 8.615237885394379%2c 76.4136864742735 9.019496659696284 M76.4136864742735 9.019496659696284 C76.22152741963166 9.360694519427145%2c 76.0293683649898 9.701892379158007%2c 75.80028387860425 10.108655082055236 M76.4136864742735 9.019496659696284 C76.22409312655645 9.356138846976165%2c 76.0344997788394 9.692781034256047%2c 75.80028387860425 10.108655082055236 M75.80028387860425 10.108655082055236 C75.6081047693814 10.403893801138077%2c 75.41592566015854 10.699132520220918%2c 75.11835896464065 11.156274872382301 M75.80028387860425 10.108655082055236 C75.58124398353827 10.445159181324042%2c 75.3622040884723 10.781663280592849%2c 75.11835896464065 11.156274872382301 M75.11835896464065 11.156274872382301 C74.92102169893646 11.420688830631171%2c 74.72368443323226 11.685102788880041%2c 74.37071390812659 12.158051136245302 M75.11835896464065 11.156274872382301 C74.93979661971387 11.3955321472199%2c 74.76123427478711 11.634789422057498%2c 74.37071390812659 12.158051136245302 M74.37071390812659 12.158051136245302 C74.10762940660578 12.467085161663865%2c 73.84454490508496 12.776119187082429%2c 73.56042094296866 13.10986736009567 M74.37071390812659 12.158051136245302 C74.09140140234295 12.486147498870583%2c 73.8120888965593 12.814243861495864%2c 73.56042094296866 13.10986736009567 M73.56042094296866 13.10986736009567 C73.25360506899942 13.426679940020632%2c 72.94678919503018 13.743492519945596%2c 72.69080973676799 14.007812326905684 M73.56042094296866 13.10986736009567 C73.25659085466462 13.42359687118375%2c 72.95276076636058 13.73732638227183%2c 72.69080973676799 14.007812326905684 M72.69080973676799 14.007812326905684 C72.38561496307592 14.284982145361607%2c 72.08042018938386 14.56215196381753%2c 71.7654537085019 14.848196188198111 M72.69080973676799 14.007812326905684 C72.40744701206147 14.265154856117299%2c 72.12408428735495 14.522497385328915%2c 71.7654537085019 14.848196188198111 M71.7654537085019 14.848196188198111 C71.42849093640214 15.116915031991702%2c 71.0915281643024 15.385633875785294%2c 70.78815534457871 15.627565626425152 M71.7654537085019 14.848196188198111 C71.45096991459349 15.09898864507484%2c 71.13648612068508 15.349781101951569%2c 70.78815534457871 15.627565626425152 M70.78815534457871 15.627565626425152 C70.4609291678067 15.855824441948423%2c 70.13370299103468 16.084083257471693%2c 69.7629305736057 16.34271804539089 M70.78815534457871 15.627565626425152 C70.50329513023804 15.826271780549273%2c 70.21843491589736 16.024977934673394%2c 69.7629305736057 16.34271804539089 M69.7629305736057 16.34271804539089 C69.54775997663782 16.4731557257556%2c 69.33258937966994 16.603593406120314%2c 68.69399226407678 16.990714730406093 M69.7629305736057 16.34271804539089 C69.48600806289888 16.510590098758673%2c 69.20908555219205 16.67846215212646%2c 68.69399226407678 16.990714730406093 M68.69399226407678 16.990714730406093 C68.25497665398441 17.219748892988363%2c 67.81596104389205 17.448783055570633%2c 67.58573291279238 17.56889292409717 M68.69399226407678 16.990714730406093 C68.27998583069099 17.206701621519684%2c 67.8659793973052 17.422688512633272%2c 67.58573291279238 17.56889292409717 M67.58573291279238 17.56889292409717 C67.24029103636953 17.721809795620388%2c 66.89484915994666 17.874726667143605%2c 66.4427065951478 18.07487676824742 M67.58573291279238 17.56889292409717 C67.13098451078096 17.770196552035568%2c 66.67623610876954 17.971500179973965%2c 66.4427065951478 18.07487676824742 M66.4427065951478 18.07487676824742 C66.09058636666836 18.204460267291566%2c 65.73846613818891 18.33404376633571%2c 65.26961025146062 18.506587066708033 M66.4427065951478 18.07487676824742 C66.17669753669638 18.172770560718323%2c 65.91068847824496 18.270664353189225%2c 65.26961025146062 18.506587066708033 M65.26961025146062 18.506587066708033 C64.84770553914453 18.631806170700422%2c 64.42580082682844 18.757025274692815%2c 64.07126438623541 18.86224982926107 M65.26961025146062 18.506587066708033 C64.81681002675623 18.640975796603417%2c 64.36400980205184 18.775364526498798%2c 64.07126438623541 18.86224982926107 M64.07126438623541 18.86224982926107 C63.682476214128805 18.95098819246448%2c 63.2936880420222 19.039726555667887%2c 62.852593259676766 19.140403561325773 M64.07126438623541 18.86224982926107 C63.72261674579417 18.941826378053307%2c 63.37396910535293 19.021402926845543%2c 62.852593259676766 19.140403561325773 M62.852593259676766 19.140403561325773 C62.44630141232323 19.206089676365558%2c 62.04000956496969 19.271775791405346%2c 61.61860465284788 19.3399052695533 M62.852593259676766 19.140403561325773 C62.53552962478513 19.19166395094984%2c 62.218465989893495 19.24292434057391%2c 61.61860465284788 19.3399052695533 M61.61860465284788 19.3399052695533 C61.13217980502618 19.386830089611188%2c 60.64575495720449 19.433754909669076%2c 60.3743692896239 19.45993515863156 M61.61860465284788 19.3399052695533 C61.2099359352327 19.379329049245595%2c 60.80126721761752 19.41875282893789%2c 60.3743692896239 19.45993515863156 M60.3743692896239 19.45993515863156 C59.937206205006184 19.473954127868925%2c 59.50004312038847 19.48797309710629%2c 59.12500000000001 19.5 M60.3743692896239 19.45993515863156 C59.911768679254926 19.474769859808628%2c 59.449168068885946 19.489604560985697%2c 59.12500000000001 19.5 M59.12500000000001 19.5 C59.12500000000001 19.5%2c 59.125 19.5%2c 59.125 19.5 M59.12500000000001 19.5 C59.12500000000001 19.5%2c 59.125 19.5%2c 59.125 19.5 M59.125 19.5 C28.738418746411234 19.5%2c -1.6481625071775312 19.5%2c -59.12499999999999 19.5 M59.125 19.5 C28.07984270303821 19.5%2c -2.96531459392358 19.5%2c -59.12499999999999 19.5 M-59.12499999999999 19.5 C-59.509497329481114 19.487669919022192%2c -59.89399465896224 19.47533983804438%2c -60.37436928962389 19.45993515863156 M-59.12499999999999 19.5 C-59.470271602093646 19.48892781175126%2c -59.81554320418731 19.47785562350252%2c -60.37436928962389 19.45993515863156 M-60.37436928962389 19.45993515863156 C-60.73620842587109 19.42502897233302%2c -61.098047562118296 19.390122786034485%2c -61.61860465284787 19.3399052695533 M-60.37436928962389 19.45993515863156 C-60.640376840961814 19.434273730074878%2c -60.906384392299735 19.408612301518193%2c -61.61860465284787 19.3399052695533 M-61.61860465284787 19.3399052695533 C-61.88922624660703 19.29615326897612%2c -62.15984784036618 19.252401268398945%2c -62.85259325967676 19.140403561325773 M-61.61860465284787 19.3399052695533 C-62.04414093120138 19.271107864152228%2c -62.46967720955489 19.202310458751157%2c -62.85259325967676 19.140403561325773 M-62.85259325967676 19.140403561325773 C-63.326421069185756 19.032255455820764%2c -63.80024887869475 18.924107350315758%2c -64.07126438623538 18.862249829261074 M-62.85259325967676 19.140403561325773 C-63.21361904414552 19.058001781934195%2c -63.574644828614275 18.975600002542613%2c -64.07126438623538 18.862249829261074 M-64.07126438623538 18.862249829261074 C-64.51256482560605 18.731274175289137%2c -64.95386526497671 18.6002985213172%2c -65.26961025146059 18.506587066708043 M-64.07126438623538 18.862249829261074 C-64.47273508806023 18.74309543232218%2c -64.87420578988508 18.623941035383282%2c -65.26961025146059 18.506587066708043 M-65.26961025146059 18.506587066708043 C-65.6234237140647 18.37638044185394%2c -65.9772371766688 18.246173816999836%2c -66.4427065951478 18.074876768247425 M-65.26961025146059 18.506587066708043 C-65.53963521370719 18.407215384517908%2c -65.80966017595378 18.307843702327773%2c -66.4427065951478 18.074876768247425 M-66.4427065951478 18.074876768247425 C-66.67577448150685 17.971704528669477%2c -66.90884236786589 17.868532289091533%2c -67.58573291279238 17.568892924097174 M-66.4427065951478 18.074876768247425 C-66.70348383493305 17.95943841987646%2c -66.96426107471831 17.844000071505494%2c -67.58573291279238 17.568892924097174 M-67.58573291279238 17.568892924097174 C-68.01611808655791 17.34436125461856%2c -68.44650326032344 17.11982958513994%2c -68.69399226407678 16.990714730406097 M-67.58573291279238 17.568892924097174 C-67.94752994730304 17.38014364293503%2c -68.30932698181368 17.19139436177288%2c -68.69399226407678 16.990714730406097 M-68.69399226407678 16.990714730406097 C-69.09700687547951 16.74640490459702%2c -69.50002148688223 16.502095078787946%2c -69.76293057360569 16.3427180453909 M-68.69399226407678 16.990714730406097 C-68.98980552454856 16.811390993516426%2c -69.28561878502035 16.632067256626755%2c -69.76293057360569 16.3427180453909 M-69.76293057360569 16.3427180453909 C-69.98132625367045 16.190374673174343%2c -70.19972193373519 16.038031300957783%2c -70.78815534457871 15.627565626425156 M-69.76293057360569 16.3427180453909 C-69.98713625008659 16.186321871185125%2c -70.21134192656751 16.029925696979348%2c -70.78815534457871 15.627565626425156 M-70.78815534457871 15.627565626425156 C-71.12996540009871 15.354981203095539%2c -71.47177545561871 15.082396779765922%2c -71.76545370850187 14.848196188198125 M-70.78815534457871 15.627565626425156 C-71.14640568370433 15.341870514414383%2c -71.50465602282993 15.056175402403609%2c -71.76545370850187 14.848196188198125 M-71.76545370850187 14.848196188198125 C-72.0664144592979 14.574871597310276%2c -72.36737521009394 14.301547006422426%2c -72.69080973676797 14.007812326905697 M-71.76545370850187 14.848196188198125 C-72.09252472518764 14.55115894466899%2c -72.41959574187342 14.254121701139852%2c -72.69080973676797 14.007812326905697 M-72.69080973676797 14.007812326905697 C-73.01738027854395 13.67060143058188%2c -73.34395082031993 13.333390534258065%2c -73.56042094296865 13.109867360095677 M-72.69080973676797 14.007812326905697 C-72.97453786470825 13.71483974029483%2c -73.25826599264855 13.421867153683962%2c -73.56042094296865 13.109867360095677 M-73.56042094296865 13.109867360095677 C-73.84543286471093 12.775076139179426%2c -74.13044478645321 12.440284918263174%2c -74.37071390812658 12.158051136245307 M-73.56042094296865 13.109867360095677 C-73.88284167042012 12.731133627372055%2c -74.2052623978716 12.352399894648432%2c -74.37071390812658 12.158051136245307 M-74.37071390812658 12.158051136245307 C-74.5222500902142 11.955006457478083%2c -74.67378627230183 11.75196177871086%2c -75.11835896464063 11.156274872382316 M-74.37071390812658 12.158051136245307 C-74.58866163435805 11.866021038541469%2c -74.8066093605895 11.57399094083763%2c -75.11835896464063 11.156274872382316 M-75.11835896464063 11.156274872382316 C-75.35859623464944 10.787205912909158%2c -75.59883350465824 10.418136953435999%2c -75.80028387860425 10.108655082055249 M-75.11835896464063 11.156274872382316 C-75.25806682280621 10.941646085427225%2c -75.39777468097179 10.727017298472134%2c -75.80028387860425 10.108655082055249 M-75.80028387860425 10.108655082055249 C-75.99264153345298 9.767104587546617%2c -76.1849991883017 9.425554093037986%2c -76.4136864742735 9.019496659696289 M-75.80028387860425 10.108655082055249 C-75.93041431981304 9.87759530655298%2c -76.06054476102184 9.646535531050711%2c -76.4136864742735 9.019496659696289 M-76.4136864742735 9.019496659696289 C-76.53616428195747 8.765168871435254%2c -76.65864208964145 8.51084108317422%2c -76.95604614880834 7.893275190886686 M-76.4136864742735 9.019496659696289 C-76.626356776194 8.577882227342887%2c -76.83902707811448 8.136267794989482%2c -76.95604614880834 7.893275190886686 M-76.95604614880834 7.893275190886686 C-77.08864058909393 7.565764359842179%2c -77.22123502937951 7.238253528797671%2c -77.42513422997033 6.73461856121551 M-76.95604614880834 7.893275190886686 C-77.0644009801005 7.625636662696914%2c -77.17275581139265 7.3579981345071435%2c -77.42513422997033 6.73461856121551 M-77.42513422997033 6.73461856121551 C-77.5626621470917 6.320406386943813%2c -77.70019006421307 5.9061942126721165%2c -77.81902313421489 5.5482879393051325 M-77.42513422997033 6.73461856121551 C-77.52171317958302 6.443738152748021%2c -77.6182921291957 6.1528577442805314%2c -77.81902313421489 5.5482879393051325 M-77.81902313421489 5.5482879393051325 C-77.90205082282164 5.2316673782197105%2c -77.9850785114284 4.915046817134289%2c -78.13609428754556 4.339158212148136 M-77.81902313421489 5.5482879393051325 C-77.93766368841212 5.095860087009637%2c -78.05630424260934 4.64343223471414%2c -78.13609428754556 4.339158212148136 M-78.13609428754556 4.339158212148136 C-78.20629423719592 3.978696307458182%2c -78.27649418684626 3.6182344027682283%2c -78.37504477658177 3.112197953150904 M-78.13609428754556 4.339158212148136 C-78.21263664139721 3.9461294023521183%2c -78.28917899524886 3.5531005925561012%2c -78.37504477658177 3.112197953150904 M-78.37504477658177 3.112197953150904 C-78.41500903489703 2.8022430574932238%2c -78.45497329321229 2.492288161835543%2c -78.53489270250937 1.872449005199809 M-78.37504477658177 3.112197953150904 C-78.42148487181011 2.752017745194049%2c -78.46792496703844 2.391837537237194%2c -78.53489270250937 1.872449005199809 M-78.53489270250937 1.872449005199809 C-78.55871058059984 1.501466328495637%2c -78.5825284586903 1.1304836517914651%2c -78.61498121591342 0.6250057626472781 M-78.53489270250937 1.872449005199809 C-78.56311053994027 1.4329334101852091%2c -78.59132837737116 0.9934178151706091%2c -78.61498121591342 0.6250057626472781 M-78.61498121591342 0.6250057626472781 C-78.61498121591342 0.23444436935796836%2c -78.61498121591342 -0.15611702393134141%2c -78.61498121591342 -0.6250057626472687 M-78.61498121591342 0.6250057626472781 C-78.61498121591342 0.14011321593026688%2c -78.61498121591342 -0.3447793307867444%2c -78.61498121591342 -0.6250057626472687 M-78.61498121591342 -0.6250057626472687 C-78.59137374645401 -0.9927111550838088%2c -78.56776627699462 -1.360416547520349%2c -78.53489270250937 -1.8724490051997822 M-78.61498121591342 -0.6250057626472687 C-78.59523222519387 -0.93261223420262%2c -78.57548323447432 -1.2402187057579712%2c -78.53489270250937 -1.8724490051997822 M-78.53489270250937 -1.8724490051997822 C-78.48085767769967 -2.291533987201145%2c -78.42682265289 -2.7106189692025078%2c -78.37504477658177 -3.112197953150895 M-78.53489270250937 -1.8724490051997822 C-78.49322693498327 -2.1956004702957603%2c -78.45156116745717 -2.5187519353917383%2c -78.37504477658177 -3.112197953150895 M-78.37504477658177 -3.112197953150895 C-78.32560032509065 -3.366084761469318%2c -78.27615587359952 -3.6199715697877415%2c -78.13609428754556 -4.339158212148126 M-78.37504477658177 -3.112197953150895 C-78.29435803118602 -3.5265073376084435%2c -78.21367128579026 -3.9408167220659918%2c -78.13609428754556 -4.339158212148126 M-78.13609428754556 -4.339158212148126 C-78.0125718978972 -4.810202618819638%2c -77.88904950824885 -5.281247025491149%2c -77.81902313421489 -5.548287939305123 M-78.13609428754556 -4.339158212148126 C-78.01481516080857 -4.801648085102334%2c -77.89353603407156 -5.264137958056542%2c -77.81902313421489 -5.548287939305123 M-77.81902313421489 -5.548287939305123 C-77.71066466287124 -5.874646390414362%2c -77.60230619152759 -6.201004841523602%2c -77.42513422997033 -6.734618561215485 M-77.81902313421489 -5.548287939305123 C-77.71196033999892 -5.8707440173438625%2c -77.60489754578298 -6.193200095382603%2c -77.42513422997033 -6.734618561215485 M-77.42513422997033 -6.734618561215485 C-77.28725470859585 -7.075183644729627%2c -77.14937518722138 -7.415748728243768%2c -76.95604614880834 -7.893275190886676 M-77.42513422997033 -6.734618561215485 C-77.27312265501567 -7.1100900902973425%2c -77.12111108006103 -7.485561619379199%2c -76.95604614880834 -7.893275190886676 M-76.95604614880834 -7.893275190886676 C-76.75033626910302 -8.32043615758111%2c -76.54462638939769 -8.747597124275542%2c -76.4136864742735 -9.019496659696282 M-76.95604614880834 -7.893275190886676 C-76.76309743530753 -8.293937322912209%2c -76.57014872180673 -8.694599454937741%2c -76.4136864742735 -9.019496659696282 M-76.4136864742735 -9.019496659696282 C-76.19007671999584 -9.416538421359194%2c -75.9664669657182 -9.813580183022104%2c -75.80028387860425 -10.108655082055243 M-76.4136864742735 -9.019496659696282 C-76.1946671818901 -9.408387591431277%2c -75.9756478895067 -9.79727852316627%2c -75.80028387860425 -10.108655082055243 M-75.80028387860425 -10.108655082055243 C-75.5575878422129 -10.481501366963204%2c -75.31489180582155 -10.854347651871164%2c -75.11835896464063 -11.156274872382308 M-75.80028387860425 -10.108655082055243 C-75.58463413801884 -10.439950993657945%2c -75.36898439743344 -10.771246905260647%2c -75.11835896464063 -11.156274872382308 M-75.11835896464063 -11.156274872382308 C-74.86516595678344 -11.495530436553413%2c -74.61197294892625 -11.834786000724517%2c -74.37071390812659 -12.158051136245302 M-75.11835896464063 -11.156274872382308 C-74.94801088960607 -11.384525773899735%2c -74.7776628145715 -11.612776675417164%2c -74.37071390812659 -12.158051136245302 M-74.37071390812659 -12.158051136245302 C-74.08067687627813 -12.498745137429127%2c -73.79063984442969 -12.839439138612953%2c -73.56042094296866 -13.10986736009567 M-74.37071390812659 -12.158051136245302 C-74.15786606093491 -12.408074328942249%2c -73.94501821374324 -12.658097521639194%2c -73.56042094296866 -13.10986736009567 M-73.56042094296866 -13.10986736009567 C-73.23103116995667 -13.449989344133858%2c -72.90164139694467 -13.790111328172044%2c -72.69080973676799 -14.007812326905677 M-73.56042094296866 -13.10986736009567 C-73.26341872561046 -13.416546533853534%2c -72.96641650825228 -13.723225707611398%2c -72.69080973676799 -14.007812326905677 M-72.69080973676799 -14.007812326905677 C-72.45042034811819 -14.226127609322745%2c -72.21003095946838 -14.444442891739811%2c -71.7654537085019 -14.848196188198107 M-72.69080973676799 -14.007812326905677 C-72.49496990417585 -14.185668881227844%2c -72.29913007158369 -14.363525435550011%2c -71.7654537085019 -14.848196188198107 M-71.7654537085019 -14.848196188198107 C-71.55508528020243 -15.015959411627941%2c -71.34471685190297 -15.183722635057773%2c -70.78815534457871 -15.627565626425149 M-71.7654537085019 -14.848196188198107 C-71.40753506101868 -15.133626784950756%2c -71.04961641353545 -15.419057381703405%2c -70.78815534457871 -15.627565626425149 M-70.78815534457871 -15.627565626425149 C-70.54992540712531 -15.793744517984859%2c -70.31169546967192 -15.95992340954457%2c -69.76293057360571 -16.342718045390885 M-70.78815534457871 -15.627565626425149 C-70.41950163598062 -15.88472249478134%2c -70.05084792738255 -16.14187936313753%2c -69.76293057360571 -16.342718045390885 M-69.76293057360571 -16.342718045390885 C-69.49576373051707 -16.504676155717863%2c -69.22859688742842 -16.66663426604484%2c -68.69399226407678 -16.99071473040609 M-69.76293057360571 -16.342718045390885 C-69.36385566872814 -16.584639597952126%2c -68.96478076385057 -16.826561150513363%2c -68.69399226407678 -16.99071473040609 M-68.69399226407678 -16.99071473040609 C-68.25543189509607 -17.219511393992008%2c -67.81687152611535 -17.44830805757793%2c -67.5857329127924 -17.56889292409717 M-68.69399226407678 -16.99071473040609 C-68.29581708849283 -17.198442464464875%2c -67.89764191290887 -17.406170198523657%2c -67.5857329127924 -17.56889292409717 M-67.5857329127924 -17.56889292409717 C-67.22798266990306 -17.72725834434038%2c -66.87023242701372 -17.88562376458359%2c -66.44270659514781 -18.07487676824742 M-67.5857329127924 -17.56889292409717 C-67.22257025270225 -17.72965426088152%2c -66.85940759261213 -17.89041559766587%2c -66.44270659514781 -18.07487676824742 M-66.44270659514781 -18.07487676824742 C-66.03431991180487 -18.22516684280274%2c -65.62593322846193 -18.375456917358058%2c -65.26961025146062 -18.506587066708033 M-66.44270659514781 -18.07487676824742 C-66.05549768593073 -18.217373226159225%2c -65.66828877671365 -18.35986968407103%2c -65.26961025146062 -18.506587066708033 M-65.26961025146062 -18.506587066708033 C-65.0181246538825 -18.58122667199438%2c -64.76663905630437 -18.655866277280726%2c -64.07126438623541 -18.862249829261067 M-65.26961025146062 -18.506587066708033 C-65.01497400459635 -18.58216176816441%2c -64.76033775773209 -18.65773646962079%2c -64.07126438623541 -18.862249829261067 M-64.07126438623541 -18.862249829261067 C-63.593265475031934 -18.971349961508857%2c -63.11526656382846 -19.08045009375665%2c -62.852593259676766 -19.140403561325773 M-64.07126438623541 -18.862249829261067 C-63.797627248404055 -18.924705720321874%2c -63.5239901105727 -18.987161611382678%2c -62.852593259676766 -19.140403561325773 M-62.852593259676766 -19.140403561325773 C-62.3782582103127 -19.21709037358371%2c -61.90392316094863 -19.293777185841645%2c -61.61860465284788 -19.3399052695533 M-62.852593259676766 -19.140403561325773 C-62.461719882416446 -19.203596937692907%2c -62.070846505156126 -19.266790314060046%2c -61.61860465284788 -19.3399052695533 M-61.61860465284788 -19.3399052695533 C-61.17334409695992 -19.382859019875642%2c -60.728083541071975 -19.42581277019799%2c -60.3743692896239 -19.45993515863156 M-61.61860465284788 -19.3399052695533 C-61.15361320590877 -19.38476243520548%2c -60.68862175896965 -19.429619600857663%2c -60.3743692896239 -19.45993515863156 M-60.3743692896239 -19.45993515863156 C-60.059575385669014 -19.47002998642223%2c -59.74478148171412 -19.4801248142129%2c -59.12500000000001 -19.5 M-60.3743692896239 -19.45993515863156 C-60.01187132848734 -19.471559762685732%2c -59.64937336735078 -19.483184366739902%2c -59.12500000000001 -19.5 M-59.12500000000001 -19.5 C-59.12500000000001 -19.5%2c -59.12500000000001 -19.5%2c -59.125 -19.5 M-59.12500000000001 -19.5 C-59.12500000000001 -19.5%2c -59.125 -19.5%2c -59.125 -19.5' stroke='%239370DB' stroke-width='1.3' fill='none' stroke-dasharray='0 0' style=''/%3e%3c/g%3e%3cg class='label' style='' transform='translate(-66.25%2c -12)'%3e%3crect/%3e%3cforeignObject width='132.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePDF extracted text%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-C1-1' data-look='classic' transform='translate(249.8046875%2c 233.8203125)'%3e%3cpolygon points='136.8203125%2c0 273.640625%2c-136.8203125 136.8203125%2c-273.640625 0%2c-136.8203125' class='label-container' transform='translate(-136.3203125%2c 136.8203125)'/%3e%3cg class='label' style='' transform='translate(-85.8203125%2c -36)'%3e%3crect/%3e%3cforeignObject width='171.640625' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCount numbered items%3cbr /%3efollowed by ring value%3cbr /%3ewithin 2 non-empty lines%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-MOD-3' data-look='classic' transform='translate(121.6015625%2c 537.4453125)'%3e%3crect class='basic label-container' style='' x='-113.6015625' y='-51' width='227.203125' height='102'/%3e%3cg class='label' style='' transform='translate(-83.6015625%2c -36)'%3e%3crect/%3e%3cforeignObject width='167.203125' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eModern format%3cbr /%3eVol. 11%2b since 2014%3cbr /%3eNumbered blip sections%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-C2-5' data-look='classic' transform='translate(378.0078125%2c 537.4453125)'%3e%3cpolygon points='92.8046875%2c0 185.609375%2c-92.8046875 92.8046875%2c-185.609375 0%2c-92.8046875' class='label-container' transform='translate(-92.3046875%2c 92.8046875)'/%3e%3cg class='label' style='' transform='translate(-53.8046875%2c -24)'%3e%3crect/%3e%3cforeignObject width='107.609375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCount isolated%3cbr /%3ering-value lines%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-INT-7' data-look='classic' transform='translate(245.47265625%2c 767.25)'%3e%3crect class='basic label-container' style='' x='-115.828125' y='-51' width='231.65625' height='102'/%3e%3cg class='label' style='' transform='translate(-85.828125%2c -36)'%3e%3crect/%3e%3cforeignObject width='171.65625' height='72'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eIntermediate format%3cbr /%3eVol. 5-10%2c 2011-2013%3cbr /%3eRing as section headers%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-EAR-9' data-look='classic' transform='translate(510.54296875%2c 767.25)'%3e%3crect class='basic label-container' style='' x='-99.2421875' y='-63' width='198.484375' height='126'/%3e%3cg class='label' style='' transform='translate(-69.2421875%2c -48)'%3e%3crect/%3e%3cforeignObject width='138.484375' height='96'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eEarly format%3cbr /%3eVol. 1-4%2c 2010-2011%3cbr /%3eNarrative prose%3cbr /%3ering = Unknown%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Early editions are the painful case. The PDF lays out blip numbers and names in a multi-column table of contents page, and when PyPDF hits the radar diagram image, the text extraction fragments. Blip numbers scatter as floating coordinates. The parser gets back something like 1 3 7 2 Evolutionary Database Design Continuous Integration with numbers and names split and shuffled. Reliable per-blip ring or quadrant assignment from text extraction alone is not achievable.
The fix is a hardcoded lookup table. _EARLY_BLIP_RANGES maps each early edition's normalized publication date string to blip number ranges per quadrant:
_EARLY_BLIP_RANGES: dict[str, dict[str, list[tuple[int, int]]]] = {
"january2010": { # Vol. 1 — 38 blips
"Techniques": [(1, 9)],
"Tools": [(10, 18)],
"Languages and Frameworks": [(19, 24)],
"Platforms": [(25, 38)],
},
"april2010": { # Vol. 2 — 59 blips
"Techniques": [(1, 13)],
"Tools": [(14, 29)],
"Languages and Frameworks": [(30, 39)],
"Platforms": [(40, 59)],
},
"august2010": { # Vol. 3 — 70 blips
"Techniques": [(1, 17)],
"Tools": [(18, 35)],
"Languages and Frameworks": [(36, 46)],
"Platforms": [(47, 70)],
},
"january2011": { # Vol. 4 — 74 blips
"Techniques": [(1, 22)],
"Tools": [(23, 41)],
"Platforms": [(42, 61)],
"Languages and Frameworks": [(62, 74)],
},
}
If ToC extraction yields fewer than half the expected blips for an early edition, the parser generates placeholder BlipMeta objects from this table with ring="Unknown" on all of them. Stage 4 of the pipeline later infers ring values from the description text. It is an ugly solution. The alternative was dropping the four oldest editions entirely.
Theme extraction adds another layer. Vol. 20–21 separate theme titles from body text with lone em-dash lines. Vol. 22–24 have an explicit "Themes for this edition" section header. Vol. 25–34 require a credits-boundary heuristic: locate the credits section, work backward to identify single-line candidate titles, and use spacing gates between candidates to decide what qualifies as a theme versus a sub-heading.
stage1_parse.py is 1,441 lines and was the part of this project I rewrote most often.
A five-stage pipeline that can be interrupted
The ingestion pipeline processes one PDF at a time through five sequential stages, each checkpointed independently so an interruption resumes from the last completed stage rather than from the beginning.
%3btext-align:center%3b%7d%23mermaid-1 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-1 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-1 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-1 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-1 .cluster text%7bfill:%23333%3b%7d%23mermaid-1 .cluster span%7bcolor:%23333%3b%7d%23mermaid-1 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-1 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-1 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-1 .icon-shape%2c%23mermaid-1 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-1 .icon-shape p%2c%23mermaid-1 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-1 .icon-shape .label rect%2c%23mermaid-1 .image-shape .label rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-1 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-1 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-1 .node .neo-node%7bstroke:%239370DB%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node rect%2c%23mermaid-1 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-1 %5bdata-look='neo'%5d.node polygon%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node path%7bstroke:%239370DB%3bstroke-width:1px%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%239370DB%3bfilter:none%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-1 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-1_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-1-subGraph2' data-look='classic'%3e%3crect style='' x='1530.484375' y='46' width='422.765625' height='260.703049659729'/%3e%3cg class='cluster-label' transform='translate(1697.84375%2c 46)'%3e%3cforeignObject width='88.046875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eQuery Layer%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='cluster' id='mermaid-1-Stores' data-look='classic'%3e%3crect style='' x='1366.5625' y='11.89102840423584' width='113.921875' height='300.00017738342285'/%3e%3cg class='cluster-label' transform='translate(1400.3984375%2c 11.89102840423584)'%3e%3cforeignObject width='46.25' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStores%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='cluster' id='mermaid-1-subGraph0' data-look='classic'%3e%3crect style='' x='204.46875' y='8' width='1000.03125' height='289.703049659729'/%3e%3cg class='cluster-label' transform='translate(641.328125%2c 8)'%3e%3cforeignObject width='126.3125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eIngestion Pipeline%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M367.719%2c164.703L371.885%2c164.703C376.052%2c164.703%2c384.385%2c164.703%2c392.052%2c164.703C399.719%2c164.703%2c406.719%2c164.703%2c410.219%2c164.703L413.719%2c164.703' id='mermaid-1-L_S1_S2_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S1_S2_0' data-points='W3sieCI6MzY3LjcxODc1LCJ5IjoxNjQuNzAzMDQ5NjU5NzI5fSx7IngiOjM5Mi43MTg3NSwieSI6MTY0LjcwMzA0OTY1OTcyOX0seyJ4Ijo0MTcuNzE4NzUsInkiOjE2NC43MDMwNDk2NTk3Mjl9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M564%2c196.749L568.167%2c198.575C572.333%2c200.401%2c580.667%2c204.052%2c588.333%2c205.877C596%2c207.703%2c603%2c207.703%2c606.5%2c207.703L610%2c207.703' id='mermaid-1-L_S2_S3_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S2_S3_0' data-points='W3sieCI6NTY0LCJ5IjoxOTYuNzQ5Mzc5ODYxOTI2MTJ9LHsieCI6NTg5LCJ5IjoyMDcuNzAzMDQ5NjU5NzI5fSx7IngiOjYxNCwieSI6MjA3LjcwMzA0OTY1OTcyOX1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M728.375%2c168.703L732.672%2c165.753C736.969%2c162.802%2c745.562%2c156.901%2c753.359%2c153.951C761.156%2c151%2c768.156%2c151%2c771.656%2c151L775.156%2c151' id='mermaid-1-L_S3_S4_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S3_S4_0' data-points='W3sieCI6NzI4LjM3NDgzODY1Njk1OTgsInkiOjE2OC43MDMwNDk2NTk3Mjl9LHsieCI6NzU0LjE1NjI1LCJ5IjoxNTF9LHsieCI6Nzc5LjE1NjI1LCJ5IjoxNTF9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M924.516%2c151L935.947%2c151C947.378%2c151%2c970.24%2c151%2c992.435%2c151C1014.63%2c151%2c1036.159%2c151%2c1046.923%2c151L1057.688%2c151' id='mermaid-1-L_S4_S5_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S4_S5_0' data-points='W3sieCI6OTI0LjUxNTYyNSwieSI6MTUxfSx7IngiOjk5My4xMDE1NjI1LCJ5IjoxNTF9LHsieCI6MTA2MS42ODc1LCJ5IjoxNTF9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M1729.758%2c108L1733.999%2c108C1738.24%2c108%2c1746.721%2c108%2c1759.029%2c112.619C1771.337%2c117.238%2c1787.47%2c126.477%2c1795.537%2c131.096L1803.604%2c135.715' id='mermaid-1-L_GR_LLM_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_GR_LLM_0' data-points='W3sieCI6MTcyOS43NTc4MTI1LCJ5IjoxMDh9LHsieCI6MTc1NS4yMDMxMjUsInkiOjEwOH0seyJ4IjoxODA3LjA3NTA4MDcyNzA3NDUsInkiOjEzNy43MDMwNDk2NTk3Mjl9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M1730.203%2c244.703L1734.37%2c244.703C1738.536%2c244.703%2c1746.87%2c244.703%2c1761.452%2c236.289C1776.034%2c227.874%2c1796.864%2c211.046%2c1807.279%2c202.631L1817.695%2c194.217' id='mermaid-1-L_VR_LLM_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_VR_LLM_0' data-points='W3sieCI6MTczMC4yMDMxMjUsInkiOjI0NC43MDMwNDk2NTk3Mjl9LHsieCI6MTc1NS4yMDMxMjUsInkiOjI0NC43MDMwNDk2NTk3Mjl9LHsieCI6MTgyMC44MDYxNTIzNDM3NSwieSI6MTkxLjcwMzA0OTY1OTcyOX1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M145.219%2c165.203L150.927%2c165.12C156.635%2c165.036%2c168.052%2c164.87%2c177.927%2c164.786C187.802%2c164.703%2c196.135%2c164.703%2c203.802%2c164.703C211.469%2c164.703%2c218.469%2c164.703%2c221.969%2c164.703L225.469%2c164.703' id='mermaid-1-L_PDFs_S1_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_PDFs_S1_0' data-points='W3sieCI6MTQ1LjIxODc1LCJ5IjoxNjUuMjAzMDQ5NjU5NzI5fSx7IngiOjE3OS40Njg3NSwieSI6MTY0LjcwMzA0OTY1OTcyOX0seyJ4IjoyMDQuNDY4NzUsInkiOjE2NC43MDMwNDk2NTk3Mjl9LHsieCI6MjI5LjQ2ODc1LCJ5IjoxNjQuNzAzMDQ5NjU5NzI5fV0=' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M529.248%2c125.703L539.207%2c115.586C549.165%2c105.469%2c569.083%2c85.234%2c592.804%2c75.117C616.526%2c65%2c644.052%2c65%2c671.578%2c65C699.104%2c65%2c726.63%2c65%2c756.673%2c65C786.716%2c65%2c819.276%2c65%2c859.1%2c65C898.924%2c65%2c946.013%2c65%2c990.806%2c65C1035.599%2c65%2c1078.096%2c65%2c1113.329%2c65C1148.563%2c65%2c1176.531%2c65%2c1204.021%2c65C1231.51%2c65%2c1258.521%2c65%2c1285.531%2c65C1312.542%2c65%2c1339.552%2c65%2c1357.284%2c68.191C1375.017%2c71.382%2c1383.471%2c77.764%2c1387.698%2c80.955L1391.925%2c84.146' id='mermaid-1-L_S2_Neo4j_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S2_Neo4j_0' data-points='W3sieCI6NTI5LjI0ODIxNDUzOTYzOTEsInkiOjEyNS43MDMwNDk2NTk3Mjl9LHsieCI6NTg5LCJ5Ijo2NX0seyJ4Ijo2NzEuNTc4MTI1LCJ5Ijo2NX0seyJ4Ijo3NTQuMTU2MjUsInkiOjY1fSx7IngiOjg1MS44MzU5Mzc1LCJ5Ijo2NX0seyJ4Ijo5OTMuMTAxNTYyNSwieSI6NjV9LHsieCI6MTEyMC41OTM3NSwieSI6NjV9LHsieCI6MTIwNC41LCJ5Ijo2NX0seyJ4IjoxMjg1LjUzMTI1LCJ5Ijo2NX0seyJ4IjoxMzY2LjU2MjUsInkiOjY1fSx7IngiOjEzOTUuMTE3MTg3NSwieSI6ODYuNTU2MDI3OTc5NzAxfV0=' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M729.156%2c233.502L733.323%2c235.368C737.49%2c237.235%2c745.823%2c240.969%2c766.27%2c242.836C786.716%2c244.703%2c819.276%2c244.703%2c859.1%2c244.703C898.924%2c244.703%2c946.013%2c244.703%2c990.806%2c244.703C1035.599%2c244.703%2c1078.096%2c244.703%2c1113.329%2c244.703C1148.563%2c244.703%2c1176.531%2c244.703%2c1204.021%2c244.703C1231.51%2c244.703%2c1258.521%2c244.703%2c1285.531%2c244.703C1312.542%2c244.703%2c1339.552%2c244.703%2c1356.557%2c244.703C1373.563%2c244.703%2c1380.563%2c244.703%2c1384.063%2c244.703L1387.563%2c244.703' id='mermaid-1-L_S3_Qdrant_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S3_Qdrant_0' data-points='W3sieCI6NzI5LjE1NjI1LCJ5IjoyMzMuNTAxNTM1OTQxNjU5fSx7IngiOjc1NC4xNTYyNSwieSI6MjQ0LjcwMzA0OTY1OTcyOX0seyJ4Ijo4NTEuODM1OTM3NSwieSI6MjQ0LjcwMzA0OTY1OTcyOX0seyJ4Ijo5OTMuMTAxNTYyNSwieSI6MjQ0LjcwMzA0OTY1OTcyOX0seyJ4IjoxMTIwLjU5Mzc1LCJ5IjoyNDQuNzAzMDQ5NjU5NzI5fSx7IngiOjEyMDQuNSwieSI6MjQ0LjcwMzA0OTY1OTcyOX0seyJ4IjoxMjg1LjUzMTI1LCJ5IjoyNDQuNzAzMDQ5NjU5NzI5fSx7IngiOjEzNjYuNTYyNSwieSI6MjQ0LjcwMzA0OTY1OTcyOX0seyJ4IjoxMzkxLjU2MjUsInkiOjI0NC43MDMwNDk2NTk3Mjl9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M1179.5%2c151L1183.667%2c151C1187.833%2c151%2c1196.167%2c151%2c1213.839%2c151C1231.51%2c151%2c1258.521%2c151%2c1285.531%2c151C1312.542%2c151%2c1339.552%2c151%2c1357.284%2c147.809C1375.017%2c144.618%2c1383.471%2c138.236%2c1387.698%2c135.045L1391.925%2c131.854' id='mermaid-1-L_S5_Neo4j_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_S5_Neo4j_0' data-points='W3sieCI6MTE3OS41LCJ5IjoxNTF9LHsieCI6MTIwNC41LCJ5IjoxNTF9LHsieCI6MTI4NS41MzEyNSwieSI6MTUxfSx7IngiOjEzNjYuNTYyNSwieSI6MTUxfSx7IngiOjEzOTUuMTE3MTg3NSwieSI6MTI5LjQ0Mzk3MjAyMDI5OX1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M1451.93%2c108L1456.689%2c108C1461.448%2c108%2c1470.966%2c108%2c1479.892%2c108C1488.818%2c108%2c1497.151%2c108%2c1505.484%2c108C1513.818%2c108%2c1522.151%2c108%2c1529.892%2c108C1537.633%2c108%2c1544.781%2c108%2c1548.355%2c108L1551.93%2c108' id='mermaid-1-L_Neo4j_GR_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Neo4j_GR_0' data-points='W3sieCI6MTQ1MS45Mjk2ODc1LCJ5IjoxMDh9LHsieCI6MTQ4MC40ODQzNzUsInkiOjEwOH0seyJ4IjoxNTA1LjQ4NDM3NSwieSI6MTA4fSx7IngiOjE1MzAuNDg0Mzc1LCJ5IjoxMDh9LHsieCI6MTU1NS45Mjk2ODc1LCJ5IjoxMDh9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M1455.484%2c244.703L1459.651%2c244.703C1463.818%2c244.703%2c1472.151%2c244.703%2c1480.484%2c244.703C1488.818%2c244.703%2c1497.151%2c244.703%2c1505.484%2c244.703C1513.818%2c244.703%2c1522.151%2c244.703%2c1529.818%2c244.703C1537.484%2c244.703%2c1544.484%2c244.703%2c1547.984%2c244.703L1551.484%2c244.703' id='mermaid-1-L_Qdrant_VR_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Qdrant_VR_0' data-points='W3sieCI6MTQ1NS40ODQzNzUsInkiOjI0NC43MDMwNDk2NTk3Mjl9LHsieCI6MTQ4MC40ODQzNzUsInkiOjI0NC43MDMwNDk2NTk3Mjl9LHsieCI6MTUwNS40ODQzNzUsInkiOjI0NC43MDMwNDk2NTk3Mjl9LHsieCI6MTUzMC40ODQzNzUsInkiOjI0NC43MDMwNDk2NTk3Mjl9LHsieCI6MTU1NS40ODQzNzUsInkiOjI0NC43MDMwNDk2NTk3Mjl9XQ==' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3cpath d='M1928.25%2c164.703L1932.417%2c164.703C1936.583%2c164.703%2c1944.917%2c164.703%2c1953.25%2c164.703C1961.583%2c164.703%2c1969.917%2c164.703%2c1977.583%2c164.703C1985.25%2c164.703%2c1992.25%2c164.703%2c1995.75%2c164.703L1999.25%2c164.703' id='mermaid-1-L_LLM_UI_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_LLM_UI_0' data-points='W3sieCI6MTkyOC4yNSwieSI6MTY0LjcwMzA0OTY1OTcyOX0seyJ4IjoxOTUzLjI1LCJ5IjoxNjQuNzAzMDQ5NjU5NzI5fSx7IngiOjE5NzguMjUsInkiOjE2NC43MDMwNDk2NTk3Mjl9LHsieCI6MjAwMy4yNSwieSI6MTY0LjcwMzA0OTY1OTcyOX1d' data-look='classic' marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S1_S2_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S2_S3_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S3_S4_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_S4_S5_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_GR_LLM_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_VR_LLM_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_PDFs_S1_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(851.8359375%2c 65)'%3e%3cg class='label' data-id='L_S2_Neo4j_0' transform='translate(-56.921875%2c -12)'%3e%3cforeignObject width='113.84375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3estructural nodes%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(993.1015625%2c 244.703049659729)'%3e%3cg class='label' data-id='L_S3_Qdrant_0' transform='translate(-43.5859375%2c -12)'%3e%3cforeignObject width='87.171875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eembeddings%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(1285.53125%2c 151)'%3e%3cg class='label' data-id='L_S5_Neo4j_0' transform='translate(-56.03125%2c -12)'%3e%3cforeignObject width='112.0625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3esemantic edges%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_Neo4j_GR_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_Qdrant_VR_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_LLM_UI_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-1-flowchart-PDFs-0' data-look='classic' transform='translate(81.234375%2c 164.703049659729)'%3e%3cpolygon points='-19.5%2c0 107.46875%2c0 126.96875%2c-39 0%2c-39' class='label-container' transform='translate(-53.734375%2c19.5)'/%3e%3cg class='label' style='' transform='translate(-46.234375%2c -12)'%3e%3crect/%3e%3cforeignObject width='92.46875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3e34 PDF Files%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-S1-1' data-look='classic' transform='translate(298.59375%2c 164.703049659729)'%3e%3crect class='basic label-container' style='' x='-69.125' y='-39' width='138.25' height='78'/%3e%3cg class='label' style='' transform='translate(-39.125%2c -24)'%3e%3crect/%3e%3cforeignObject width='78.25' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStage 1%3cbr /%3ePDF Parse%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-S2-2' data-look='classic' transform='translate(490.859375%2c 164.703049659729)'%3e%3crect class='basic label-container' style='' x='-73.140625' y='-39' width='146.28125' height='78'/%3e%3cg class='label' style='' transform='translate(-43.140625%2c -24)'%3e%3crect/%3e%3cforeignObject width='86.28125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStage 2%3cbr /%3eGraph Seed%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-S3-3' data-look='classic' transform='translate(671.578125%2c 207.703049659729)'%3e%3crect class='basic label-container' style='' x='-57.578125' y='-39' width='115.15625' height='78'/%3e%3cg class='label' style='' transform='translate(-27.578125%2c -24)'%3e%3crect/%3e%3cforeignObject width='55.15625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStage 3%3cbr /%3eEmbed%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-S4-4' data-look='classic' transform='translate(851.8359375%2c 151)'%3e%3crect class='basic label-container' style='' x='-72.6796875' y='-39' width='145.359375' height='78'/%3e%3cg class='label' style='' transform='translate(-42.6796875%2c -24)'%3e%3crect/%3e%3cforeignObject width='85.359375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStage 4%3cbr /%3eLLM Extract%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-S5-5' data-look='classic' transform='translate(1120.59375%2c 151)'%3e%3crect class='basic label-container' style='' x='-58.90625' y='-39' width='117.8125' height='78'/%3e%3cg class='label' style='' transform='translate(-28.90625%2c -24)'%3e%3crect/%3e%3cforeignObject width='57.8125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStage 5%3cbr /%3eResolve%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-Neo4j-11' data-look='classic' transform='translate(1423.5234375%2c 108)'%3e%3cpath d='M0%2c7.811962873839808 a28.40625%2c7.811962873839808 0%2c0%2c0 56.8125%2c0 a28.40625%2c7.811962873839808 0%2c0%2c0 -56.8125%2c0 l0%2c46.81196287383981 a28.40625%2c7.811962873839808 0%2c0%2c0 56.8125%2c0 l0%2c-46.81196287383981' class='basic label-container outer-path' style='' transform='translate(-28.40625%2c -31.217944310759712)'/%3e%3cg class='label' style='' transform='translate(-20.90625%2c -2)'%3e%3crect/%3e%3cforeignObject width='41.8125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eNeo4j%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-Qdrant-12' data-look='classic' transform='translate(1423.5234375%2c 244.703049659729)'%3e%3cpath d='M0%2c8.45877098668431 a31.9609375%2c8.45877098668431 0%2c0%2c0 63.921875%2c0 a31.9609375%2c8.45877098668431 0%2c0%2c0 -63.921875%2c0 l0%2c47.458770986684314 a31.9609375%2c8.45877098668431 0%2c0%2c0 63.921875%2c0 l0%2c-47.458770986684314' class='basic label-container outer-path' style='' transform='translate(-31.9609375%2c -32.188156480026464)'/%3e%3cg class='label' style='' transform='translate(-24.4609375%2c -2)'%3e%3crect/%3e%3cforeignObject width='48.921875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eQdrant%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-GR-13' data-look='classic' transform='translate(1642.84375%2c 108)'%3e%3crect class='basic label-container' style='' x='-86.9140625' y='-27' width='173.828125' height='54'/%3e%3cg class='label' style='' transform='translate(-56.9140625%2c -12)'%3e%3crect/%3e%3cforeignObject width='113.828125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eGraph Retriever%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-VR-14' data-look='classic' transform='translate(1642.84375%2c 244.703049659729)'%3e%3crect class='basic label-container' style='' x='-87.359375' y='-27' width='174.71875' height='54'/%3e%3cg class='label' style='' transform='translate(-57.359375%2c -12)'%3e%3crect/%3e%3cforeignObject width='114.71875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eVector Retriever%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-LLM-15' data-look='classic' transform='translate(1854.2265625%2c 164.703049659729)'%3e%3crect class='basic label-container' style='' x='-74.0234375' y='-27' width='148.046875' height='54'/%3e%3cg class='label' style='' transform='translate(-44.0234375%2c -12)'%3e%3crect/%3e%3cforeignObject width='88.046875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eLLM Answer%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-1-flowchart-UI-20' data-look='classic' transform='translate(2083.9375%2c 164.703049659729)'%3e%3crect class='basic label-container' style='' x='-80.6875' y='-27' width='161.375' height='54'/%3e%3cg class='label' style='' transform='translate(-50.6875%2c -12)'%3e%3crect/%3e%3cforeignObject width='101.375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eStreamlit Chat%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-1-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
After each stage completes for a given file, pipeline_checkpoint.json records a boolean flag keyed as "{file_key}.s{stage}". Serialized RadarMeta and BlipSemantics are also cached in the checkpoint so subsequent stages can load them without re-parsing or re-calling the LLM. The --stage N CLI flag clears the checkpoint for a specific stage and all later ones across all files, forcing a re-run from that point.
Stage 1 extracts structural metadata from the PDF: blip number, name, ring, quadrant, description. No LLM is involved. These facts are printed in the document; using a language model to extract them would add cost, latency, and hallucination risk for information that regex handles without ambiguity. The output is a RadarMeta Pydantic model with a list of BlipMeta objects. RadarMeta computes a stable edition_id property (radar-vol-5, radar-jan-2010) used as the Neo4j RadarEdition node ID across all subsequent stages.
Stage 2 seeds the knowledge graph. Every write uses MERGE on unique constraints, making the stage fully idempotent: running it twice produces the same graph. Eight node labels get unique constraints applied before the file loop starts. Blip IDs are edition-scoped ({edition_id}-blip-{number}) to prevent collisions between blips with the same sequential number across different editions. IN_RING edges are skipped when ring="Unknown" (early editions); the UnknownCollector records each skip.
Stage 3 chunks blip descriptions at blank lines, merging short adjacent paragraphs up to 300 words (a whitespace-split approximation, fast enough for this use case). Chunks embed in batches of 32. When the embedding API returns HTTP 431 (request too large), the batch halves automatically and retries. Qdrant point IDs use uuid5(NAMESPACE_DNS, doc_id) for deterministic, idempotent upserts. Stage 3 also creates Document nodes in Neo4j with CHUNK_OF edges back to their parent Blip or Theme, and NEXT_CHUNK edges forming a linked list of chunks within each blip.
Stage 4 is the most expensive. One structured output call to llm_small (gpt-4o-mini or llama3.2:3b) extracts a BlipSemantics object per blip. The small model keeps ingestion costs low; entity extraction and relationship classification don't require the full model. All blip calls for an edition run concurrently under asyncio.Semaphore(2) via asyncio.gather(), with tenacity handling retries at exponential backoff (2–60 seconds, 4 attempts).
What makes Stage 4 actually work is enforcing the relationship vocabulary at the type level:
BlipRelType = Literal[
"COMPLEMENTS",
"REFERENCES",
"WARNS_ABOUT",
"MITIGATES",
"ALTERNATIVE_TO",
"PART_OF_ECOSYSTEM",
]
class BlipRelation(BaseModel):
name: str
relationship: BlipRelType
Without this, the LLM invents relationship type names ("USES", "DEPENDS_ON", "COMPATIBLE_WITH") that don't correspond to Neo4j edge types. The Literal type in Pydantic v2 structured output restricts the model to exactly those six strings. The same pattern applies to TechRelType (four types for blip-to-technology edges) and the 25-item VALID_TAGS closed list. BlipSemantics also carries ring_inference: when ring="Unknown", the LLM reads the description language and infers the ring value ("we recommend" → Adopt, "worth exploring" → Assess, "we advise against" → Hold).
Stage 5 resolves the LLM's blip name references to actual blip IDs. The LLM in Stage 4 names blips by their text label, and those names sometimes have minor variations or typos. Stage 5 first tries an exact case-insensitive match; if that fails, it uses difflib.get_close_matches() with a 0.7 similarity cutoff. Resolved references become Neo4j edges via MERGE. Ring inference from Stage 4 is applied here: early-edition blips get their ring property updated and the missing IN_RING edge created. shortSummary is written to each Blip node.
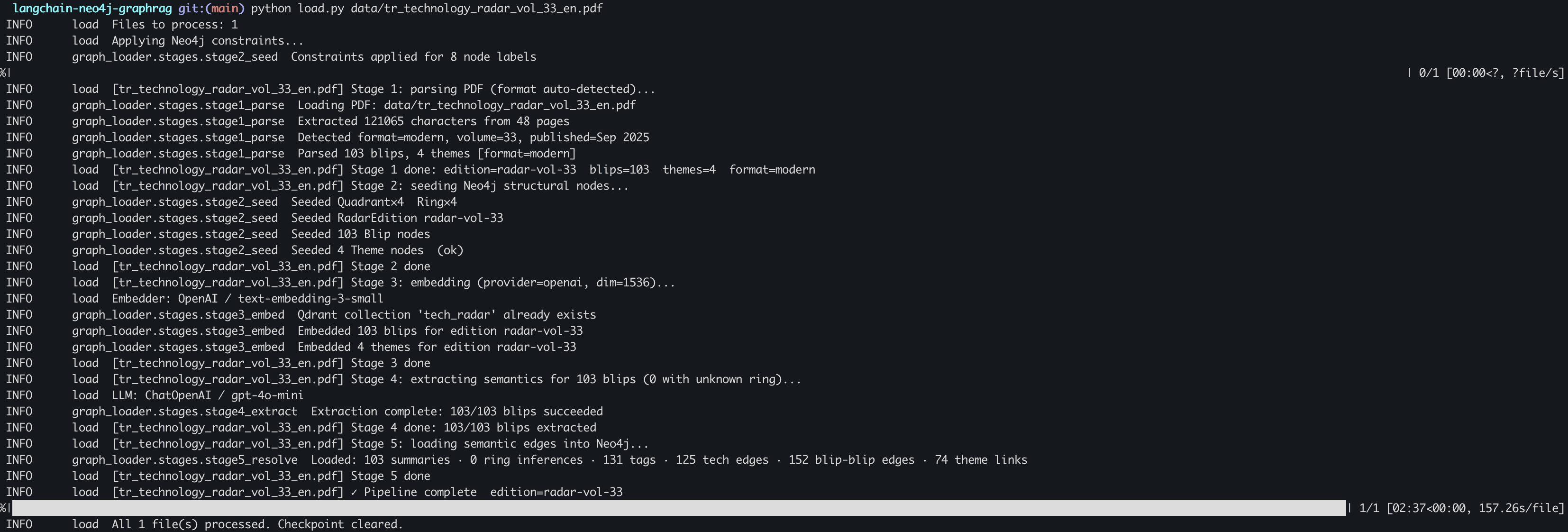
The knowledge graph schema
After all five stages run across all 34 editions, the graph contains eight node types connected by twelve relationship types.
%3btext-align:center%3b%7d%23mermaid-2 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-2 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-2 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-2 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-2 .cluster text%7bfill:%23333%3b%7d%23mermaid-2 .cluster span%7bcolor:%23333%3b%7d%23mermaid-2 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-2 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-2 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-2 .icon-shape%2c%23mermaid-2 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-2 .icon-shape p%2c%23mermaid-2 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-2 .icon-shape .label rect%2c%23mermaid-2 .image-shape .label rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-2 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-2 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-2 .node .neo-node%7bstroke:%239370DB%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node rect%2c%23mermaid-2 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-2 %5bdata-look='neo'%5d.node polygon%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node path%7bstroke:%239370DB%3bstroke-width:1px%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%239370DB%3bfilter:none%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-2 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-2 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-2_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M109.689%2c490.05L128.698%2c469.875C147.707%2c449.7%2c185.725%2c409.35%2c215.533%2c389.175C245.341%2c369%2c266.94%2c369%2c277.74%2c369L288.539%2c369' id='mermaid-2-L_RE_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_RE_B_0' data-points='W3sieCI6MTA5LjY4OTMwNDcxMTExODE4LCJ5Ijo0OTAuMDUwMDAwMDAwNzQ1MDZ9LHsieCI6MjIzLjc0MjE4NzUsInkiOjM2OX0seyJ4IjoyOTIuNTM5MDYyNSwieSI6MzY5fV0=' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M106.398%2c544.05L125.955%2c567.892C145.513%2c591.733%2c184.628%2c639.417%2c222.875%2c663.258C261.122%2c687.1%2c298.503%2c687.1%2c344.992%2c687.1C391.482%2c687.1%2c447.081%2c687.1%2c501.244%2c661.068C555.408%2c635.037%2c608.136%2c582.974%2c634.5%2c556.942L660.864%2c530.91' id='mermaid-2-L_RE_T_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_RE_T_0' data-points='W3sieCI6MTA2LjM5ODEyNzM4ODkwNjE5LCJ5Ijo1NDQuMDUwMDAwMDAwNzQ1MX0seyJ4IjoyMjMuNzQyMTg3NSwieSI6Njg3LjEwMDAwMDAwMTQ5MDF9LHsieCI6MzM1Ljg4MjgxMjUsInkiOjY4Ny4xMDAwMDAwMDE0OTAxfSx7IngiOjUwMi42Nzk2ODc1LCJ5Ijo2ODcuMTAwMDAwMDAxNDkwMX0seyJ4Ijo2NjMuNzA5OTI5NDM1NDgzOSwieSI6NTI4LjEwMDAwMDAwMTQ5MDF9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M349.366%2c342L374.919%2c290.833C400.471%2c239.667%2c451.575%2c137.333%2c497.297%2c86.167C543.018%2c35%2c583.357%2c35%2c603.526%2c35L623.695%2c35' id='mermaid-2-L_B_Q_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_Q_0' data-points='W3sieCI6MzQ5LjM2NjM5MjIxNTU2ODg1LCJ5IjozNDJ9LHsieCI6NTAyLjY3OTY4NzUsInkiOjM1fSx7IngiOjYyNy42OTUzMTI1LCJ5IjozNX1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M355.463%2c342L379.999%2c308.167C404.535%2c274.333%2c453.608%2c206.667%2c501.131%2c172.833C548.654%2c139%2c594.628%2c139%2c617.615%2c139L640.602%2c139' id='mermaid-2-L_B_R_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_R_0' data-points='W3sieCI6MzU1LjQ2MzMxNTIxNzM5MTMsInkiOjM0Mn0seyJ4Ijo1MDIuNjc5Njg3NSwieSI6MTM5fSx7IngiOjY0NC42MDE1NjI1LCJ5IjoxMzl9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M371.625%2c342L393.467%2c325.5C415.31%2c309%2c458.995%2c276%2c500.49%2c259.5C541.984%2c243%2c581.289%2c243%2c600.941%2c243L620.594%2c243' id='mermaid-2-L_B_D_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_D_0' data-points='W3sieCI6MzcxLjYyNSwieSI6MzQyfSx7IngiOjUwMi42Nzk2ODc1LCJ5IjoyNDN9LHsieCI6NjI0LjU5Mzc1LCJ5IjoyNDN9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M757.516%2c235.991L774.137%2c234.239C790.758%2c232.486%2c824%2c228.98%2c856.573%2c227.228C889.146%2c225.475%2c921.049%2c225.475%2c937.001%2c225.475L952.953%2c225.475' id='mermaid-2-D-cyclic-special-1' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='D-cyclic-special-1' data-points='W3sieCI6NzU3LjUxNTYyNSwieSI6MjM1Ljk5MTQ4MjkzNTE2NTA0fSx7IngiOjg1Ny4yNDIxODc1LCJ5IjoyMjUuNDc0OTk5OTk5NjI3NDd9LHsieCI6OTUyLjk1MzEyNSwieSI6MjI1LjQ3NDk5OTk5OTYyNzQ3fV0=' data-look='classic'/%3e%3cpath d='M953.053%2c225.475L966.259%2c225.475C979.465%2c225.475%2c1005.876%2c225.475%2c1032.288%2c228.394C1058.699%2c231.313%2c1085.11%2c237.151%2c1098.316%2c240.07L1111.522%2c242.989' id='mermaid-2-D-cyclic-special-mid' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='D-cyclic-special-mid' data-points='W3sieCI6OTUzLjA1MzEyNTAwMTQ5MDEsInkiOjIyNS40NzQ5OTk5OTk2Mjc0N30seyJ4IjoxMDMyLjI4NzUwMDAwMTQ5MDEsInkiOjIyNS40NzQ5OTk5OTk2Mjc0N30seyJ4IjoxMTExLjUyMTg3NTAwMTQ5MDEsInkiOjI0Mi45ODg5NDgwMTEzNDQzOH1d' data-look='classic'/%3e%3cpath d='M1111.522%2c243.046L1098.316%2c255.205C1085.11%2c267.364%2c1058.699%2c291.682%2c1032.279%2c303.841C1005.859%2c316%2c979.431%2c316%2c950.257%2c316C921.083%2c316%2c889.163%2c316%2c856.359%2c308.601C823.556%2c301.203%2c789.87%2c286.406%2c773.027%2c279.007L756.184%2c271.609' id='mermaid-2-D-cyclic-special-2' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='D-cyclic-special-2' data-points='W3sieCI6MTExMS41MjE4NzUwMDE0OTAxLCJ5IjoyNDMuMDQ2MDM2ODE0MzcwNX0seyJ4IjoxMDMyLjI4NzUwMDAwMTQ5MDEsInkiOjMxNn0seyJ4Ijo5NTMuMDAzMTI1MDAwNzQ1MSwieSI6MzE2fSx7IngiOjg1Ny4yNDIxODc1LCJ5IjozMTZ9LHsieCI6NzUyLjUyMTI5NzA4OTA0MTEsInkiOjI3MH1d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M379.227%2c363.283L399.802%2c360.569C420.378%2c357.855%2c461.529%2c352.428%2c505.684%2c349.714C549.839%2c347%2c596.997%2c347%2c620.577%2c347L644.156%2c347' id='mermaid-2-L_B_TAG_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_TAG_0' data-points='W3sieCI6Mzc5LjIyNjU2MjUsInkiOjM2My4yODMwOTEzMzQ4OTQ2fSx7IngiOjUwMi42Nzk2ODc1LCJ5IjozNDd9LHsieCI6NjQ4LjE1NjI1LCJ5IjozNDd9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M379.227%2c382.142L399.802%2c388.381C420.378%2c394.62%2c461.529%2c407.097%2c503.738%2c422.699C545.948%2c438.301%2c589.217%2c457.027%2c610.851%2c466.389L632.485%2c475.752' id='mermaid-2-L_B_T_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_T_0' data-points='W3sieCI6Mzc5LjIyNjU2MjUsInkiOjM4Mi4xNDIzOTM0NDI5MTM0fSx7IngiOjUwMi42Nzk2ODc1LCJ5Ijo0MTkuNTc1MDAwMDAxMTE3Nn0seyJ4Ijo2MzYuMTU2MjUsInkiOjQ3Ny4zNDEwMzQ1NDg0OTUwM31d' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M379.227%2c390.458L399.802%2c400.644C420.378%2c410.83%2c461.529%2c431.203%2c513.492%2c436.803C565.455%2c442.402%2c628.23%2c433.23%2c659.617%2c428.644L691.005%2c424.057' id='mermaid-2-B-cyclic-special-1' class='edge-thickness-normal edge-pattern-dotted edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='B-cyclic-special-1' data-points='W3sieCI6Mzc5LjIyNjU2MjUsInkiOjM5MC40NTc4OTY5NTU3OTM5fSx7IngiOjUwMi42Nzk2ODc1LCJ5Ijo0NTEuNTc1MDAwMDAxMTE3Nn0seyJ4Ijo2OTEuMDA0Njg3NDk5MjU0OSwieSI6NDI0LjA1NzMwNTkwNjYyNzF9XQ==' data-look='classic'/%3e%3cpath d='M691.105%2c424.05L718.794%2c424.05C746.484%2c424.05%2c801.863%2c424.05%2c845.504%2c439.796C889.146%2c455.542%2c921.049%2c487.034%2c937.001%2c502.78L952.953%2c518.526' id='mermaid-2-B-cyclic-special-mid' class='edge-thickness-normal edge-pattern-dotted edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='B-cyclic-special-mid' data-points='W3sieCI6NjkxLjEwNDY4NzUwMDc0NTEsInkiOjQyNC4wNTAwMDAwMDA3NDUwNn0seyJ4Ijo4NTcuMjQyMTg3NSwieSI6NDI0LjA1MDAwMDAwMDc0NTA2fSx7IngiOjk1Mi45NTMxMjUsInkiOjUxOC41MjU2NDUzMjQ4Mzk0fV0=' data-look='classic'/%3e%3cpath d='M952.971%2c518.625L937.016%2c543.371C921.061%2c568.117%2c889.152%2c617.608%2c845.499%2c642.354C801.846%2c667.1%2c746.451%2c667.1%2c687.357%2c667.1C628.263%2c667.1%2c565.471%2c667.1%2c509.119%2c622.498C452.768%2c577.897%2c402.855%2c488.694%2c377.899%2c444.092L352.943%2c399.491' id='mermaid-2-B-cyclic-special-2' class='edge-thickness-normal edge-pattern-dotted edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='B-cyclic-special-2' data-points='W3sieCI6OTUyLjk3MDg4NzY4NzUyMjYsInkiOjUxOC42MjUwMDAwMDE4NjI2fSx7IngiOjg1Ny4yNDIxODc1LCJ5Ijo2NjcuMTAwMDAwMDAxNDkwMX0seyJ4Ijo2OTEuMDU0Njg3NSwieSI6NjY3LjEwMDAwMDAwMTQ5MDF9LHsieCI6NTAyLjY3OTY4NzUsInkiOjY2Ny4xMDAwMDAwMDE0OTAxfSx7IngiOjM1MC45OTAyMTE0NDMyMzIxLCJ5IjozOTZ9XQ==' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3cpath d='M354.957%2c396L379.578%2c430.85C404.198%2c465.7%2c453.439%2c535.4%2c497.042%2c570.25C540.646%2c605.1%2c578.612%2c605.1%2c597.595%2c605.1L616.578%2c605.1' id='mermaid-2-L_B_TECH_0' class='edge-thickness-normal edge-pattern-dotted edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_TECH_0' data-points='W3sieCI6MzU0Ljk1NzQyMzM2MzkyMDI3LCJ5IjozOTZ9LHsieCI6NTAyLjY3OTY4NzUsInkiOjYwNS4xMDAwMDAwMDE0OTAxfSx7IngiOjYyMC41NzgxMjUsInkiOjYwNS4xMDAwMDAwMDE0OTAxfV0=' data-look='classic' marker-end='url(%23mermaid-2_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel' transform='translate(223.7421875%2c 369)'%3e%3cg class='label' data-id='L_RE_B_0' transform='translate(-38.2421875%2c -12)'%3e%3cforeignObject width='76.484375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eHAS_BLIP%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(335.8828125%2c 687.1000000014901)'%3e%3cg class='label' data-id='L_RE_T_0' transform='translate(-48.8984375%2c -12)'%3e%3cforeignObject width='97.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eHAS_THEME%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(502.6796875%2c 35)'%3e%3cg class='label' data-id='L_B_Q_0' transform='translate(-57.34375%2c -12)'%3e%3cforeignObject width='114.6875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eIN_QUADRANT%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(502.6796875%2c 139)'%3e%3cg class='label' data-id='L_B_R_0' transform='translate(-32.453125%2c -12)'%3e%3cforeignObject width='64.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eIN_RING%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(502.6796875%2c 243)'%3e%3cg class='label' data-id='L_B_D_0' transform='translate(-44.0078125%2c -12)'%3e%3cforeignObject width='88.015625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eCHUNK_OF%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='D-cyclic-special-1' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(1032.2875000014901%2c 225.47499999962747)'%3e%3cg class='label' data-id='D-cyclic-special-mid' transform='translate(-54.234375%2c -12)'%3e%3cforeignObject width='108.46875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eNEXT_CHUNK%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='D-cyclic-special-2' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(502.6796875%2c 347)'%3e%3cg class='label' data-id='L_B_TAG_0' transform='translate(-58.078125%2c -12)'%3e%3cforeignObject width='116.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eTAGGED_WITH%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(502.6796875%2c 419.5750000011176)'%3e%3cg class='label' data-id='L_B_T_0' transform='translate(-92.8984375%2c -12)'%3e%3cforeignObject width='185.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3eMENTIONED_IN_THEME%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='B-cyclic-special-1' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(857.2421875%2c 424.05000000074506)'%3e%3cg class='label' data-id='B-cyclic-special-mid' transform='translate(-70.7109375%2c -12)'%3e%3cforeignObject width='141.421875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3esemantic blip edges%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='B-cyclic-special-2' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(502.6796875%2c 605.1000000014901)'%3e%3cg class='label' data-id='L_B_TECH_0' transform='translate(-82.28125%2c -12)'%3e%3cforeignObject width='164.5625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3etech relationship edges%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-2-flowchart-RE-0' data-look='classic' transform='translate(84.25%2c 517.0500000007451)'%3e%3crect class='basic label-container' style='' x='-76.25' y='-27' width='152.5' height='54'/%3e%3cg class='label' style='' transform='translate(-46.25%2c -12)'%3e%3crect/%3e%3cforeignObject width='92.5' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRadarEdition%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-B-1' data-look='classic' transform='translate(335.8828125%2c 369)'%3e%3crect class='basic label-container' style='' x='-43.34375' y='-27' width='86.6875' height='54'/%3e%3cg class='label' style='' transform='translate(-13.34375%2c -12)'%3e%3crect/%3e%3cforeignObject width='26.6875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eBlip%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-Q-2' data-look='classic' transform='translate(691.0546875%2c 35)'%3e%3crect class='basic label-container' style='' x='-63.359375' y='-27' width='126.71875' height='54'/%3e%3cg class='label' style='' transform='translate(-33.359375%2c -12)'%3e%3crect/%3e%3cforeignObject width='66.71875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eQuadrant%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-R-3' data-look='classic' transform='translate(691.0546875%2c 139)'%3e%3crect class='basic label-container' style='' x='-46.453125' y='-27' width='92.90625' height='54'/%3e%3cg class='label' style='' transform='translate(-16.453125%2c -12)'%3e%3crect/%3e%3cforeignObject width='32.90625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRing%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-T-4' data-look='classic' transform='translate(691.0546875%2c 501.1000000014901)'%3e%3crect class='basic label-container' style='' x='-54.8984375' y='-27' width='109.796875' height='54'/%3e%3cg class='label' style='' transform='translate(-24.8984375%2c -12)'%3e%3crect/%3e%3cforeignObject width='49.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTheme%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-D-5' data-look='classic' transform='translate(691.0546875%2c 243)'%3e%3crect class='basic label-container' style='' x='-66.4609375' y='-27' width='132.921875' height='54'/%3e%3cg class='label' style='' transform='translate(-36.4609375%2c -12)'%3e%3crect/%3e%3cforeignObject width='72.921875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDocument%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-TAG-6' data-look='classic' transform='translate(691.0546875%2c 347)'%3e%3crect class='basic label-container' style='' x='-42.8984375' y='-27' width='85.796875' height='54'/%3e%3cg class='label' style='' transform='translate(-12.8984375%2c -12)'%3e%3crect/%3e%3cforeignObject width='25.796875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTag%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-2-flowchart-TECH-7' data-look='classic' transform='translate(691.0546875%2c 605.1000000014901)'%3e%3crect class='basic label-container' style='' x='-70.4765625' y='-27' width='140.953125' height='54'/%3e%3cg class='label' style='' transform='translate(-40.4765625%2c -12)'%3e%3crect/%3e%3cforeignObject width='80.953125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTechnology%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='label edgeLabel' id='D---D---1' transform='translate(953.0031250007451%2c 225.47499999962747)'%3e%3crect width='0.1' height='0.1'/%3e%3cg class='label' style='' transform='translate(0%2c 0)'%3e%3crect/%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 10px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='label edgeLabel' id='D---D---2' transform='translate(1111.5718750022352%2c 243)'%3e%3crect width='0.1' height='0.1'/%3e%3cg class='label' style='' transform='translate(0%2c 0)'%3e%3crect/%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 10px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='label edgeLabel' id='B---B---1' transform='translate(691.0546875%2c 424.05000000074506)'%3e%3crect width='0.1' height='0.1'/%3e%3cg class='label' style='' transform='translate(0%2c 0)'%3e%3crect/%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 10px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='label edgeLabel' id='B---B---2' transform='translate(953.0031250007451%2c 518.5750000011176)'%3e%3crect width='0.1' height='0.1'/%3e%3cg class='label' style='' transform='translate(0%2c 0)'%3e%3crect/%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 10px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-2-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Solid edges are structural, created deterministically in Stages 2 and 3. Dashed edges are semantic, created by the LLM in Stage 4 and resolved in Stage 5. The six blip-to-blip semantic relationship types are COMPLEMENTS, REFERENCES, WARNS_ABOUT, MITIGATES, ALTERNATIVE_TO, and PART_OF_ECOSYSTEM. The four blip-to-technology types are INTEGRATES_WITH, BUILT_ON, RUNS_ON, and ALTERNATIVE_TO. Ring.weight (Adopt=3, Trial=2, Assess=1, Hold=0) encodes canonical ring ordering as a numeric property so Cypher queries can sort without string comparison.
A multi-hop query illustrating what the graph structure enables: finding Adopt-ring blips that complement an observability-tagged blip.
MATCH (b:Blip)-[:TAGGED_WITH]->(:Tag {name: "observability"})
WITH collect(b) AS obs_blips
MATCH (a:Blip)-[:IN_RING]->(:Ring {name: "Adopt"})
WHERE any(ob IN obs_blips WHERE (a)-[:COMPLEMENTS]->(ob))
RETURN a.name, a.shortSummary
That query requires knowing which blips are tagged observability, which other blips explicitly complement them, and what ring those complementing blips are in. Three traversal hops, all typed. Vector similarity alone cannot express it.
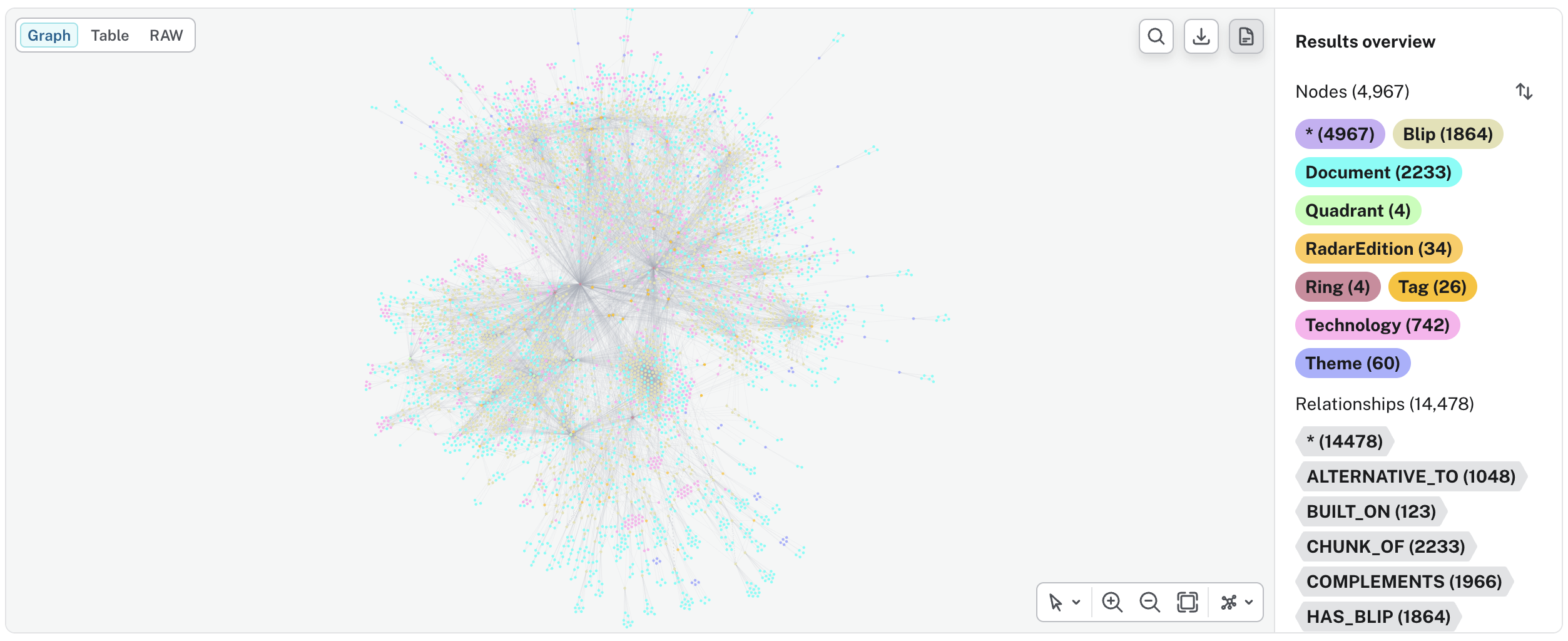
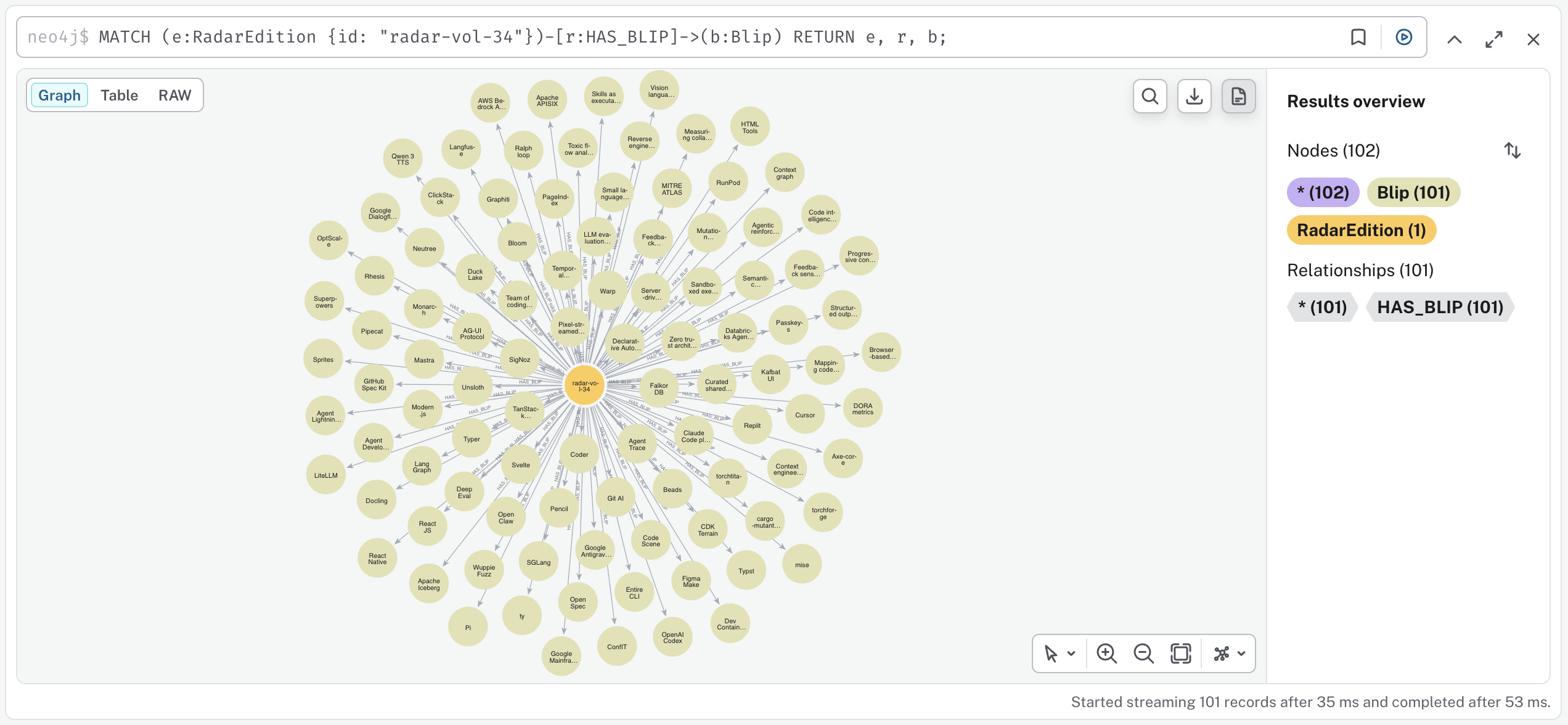
Asking questions across fifteen years of data
At query time, the application runs a graph retriever and a vector retriever, combines their output, and passes the combined context to the large LLM for a final answer.
)%3b%7d%23mermaid-3 rect.note%5bdata-look='neo'%5d%7bstroke:%23aaaa33%3bfill:%23fff5ad%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-3 text.actor%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .actor-line%7bstroke:%239370DB%3b%7d%23mermaid-3 .innerArc%7bstroke-width:1.5%3bstroke-dasharray:none%3b%7d%23mermaid-3 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-3 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-3 %5bid%24='-arrowhead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-3 .sequenceNumber%7bfill:white%3b%7d%23mermaid-3 %5bid%24='-sequencenumber'%5d%7bfill:%23333%3b%7d%23mermaid-3 %5bid%24='-crosshead'%5d path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-3 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-3 .labelBox%7bstroke:%239370DB%3bfill:%23ECECFF%3bfilter:none%3b%7d%23mermaid-3 .labelText%2c%23mermaid-3 .labelText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .loopText%2c%23mermaid-3 .loopText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .sectionTitle%2c%23mermaid-3 .sectionTitle%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:%239370DB%3bfill:%239370DB%3b%7d%23mermaid-3 .note%7bstroke:%23aaaa33%3bfill:%23fff5ad%3b%7d%23mermaid-3 .noteText%2c%23mermaid-3 .noteText%26gt%3btspan%7bfill:black%3bstroke:none%3bfont-weight:normal%3b%7d%23mermaid-3 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-3 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23ECECFF%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-3 .actor-man circle%2c%23mermaid-3 line%7bfill:%23ECECFF%3bstroke-width:2px%3b%7d%23mermaid-3 g rect.rect%7bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3bstroke:%239370DB%3b%7d%23mermaid-3 .node .neo-node%7bstroke:%239370DB%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node rect%2c%23mermaid-3 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-3 %5bdata-look='neo'%5d.node polygon%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node path%7bstroke:%239370DB%3bstroke-width:1px%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%239370DB%3bfilter:none%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-3 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-3 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol id='mermaid-3-computer' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-3-database' fill-rule='evenodd' clip-rule='evenodd'%3e%3cpath transform='scale(.5)' d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol id='mermaid-3-clock' width='24' height='24'%3e%3cpath transform='scale(.5)' d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-3-arrowhead' refX='7.9' refY='5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-3-crosshead' markerWidth='15' markerHeight='8' orient='auto' refX='4' refY='4.5'%3e%3cpath fill='none' stroke='black' stroke-width='1pt' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' style='stroke-dasharray: 0%2c 0%3b'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-3-filled-head' refX='15.5' refY='7' markerWidth='20' markerHeight='28' orient='auto'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-3-sequencenumber' refX='15' refY='15' markerWidth='60' markerHeight='40' orient='auto'%3e%3ccircle cx='15' cy='15' r='6'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-3-solidTopArrowHead' refX='7.9' refY='7.25' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 8 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-3-solidBottomArrowHead' refX='7.9' refY='0.75' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 10 0 L 0 8 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-3-stickTopArrowHead' refX='7.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 0 L 7 7' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker id='mermaid-3-stickBottomArrowHead' refX='7.5' refY='0' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto-start-reverse'%3e%3cpath d='M 0 7 L 7 0' stroke='black' stroke-width='1.5' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cg data-et='control-structure' data-id='i5'%3e%3cline x1='495' y1='163' x2='822' y2='163' class='loopLine'/%3e%3cline x1='822' y1='163' x2='822' y2='296' class='loopLine'/%3e%3cline x1='495' y1='296' x2='822' y2='296' class='loopLine'/%3e%3cline x1='495' y1='163' x2='495' y2='296' class='loopLine'/%3e%3cpolygon points='495%2c163 545%2c163 545%2c176 536.6%2c183 495%2c183' class='labelBox'/%3e%3ctext x='520' y='176' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='labelText' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eopt%3c/text%3e%3ctext x='683.5' y='181' text-anchor='middle' class='loopText' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3e%3ctspan x='683.5'%3e%5bhistory is non-empty%5d%3c/tspan%3e%3c/text%3e%3c/g%3e%3cg data-et='control-structure' data-id='i16'%3e%3cline x1='495' y1='394' x2='1222' y2='394' class='loopLine'/%3e%3cline x1='1222' y1='394' x2='1222' y2='752' class='loopLine'/%3e%3cline x1='495' y1='752' x2='1222' y2='752' class='loopLine'/%3e%3cline x1='495' y1='394' x2='495' y2='752' class='loopLine'/%3e%3cline x1='495' y1='624' x2='1222' y2='624' class='loopLine' style='stroke-dasharray: 3%2c 3%3b'/%3e%3cpolygon points='495%2c394 545%2c394 545%2c407 536.6%2c414 495%2c414' class='labelBox'/%3e%3ctext x='520' y='407' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='labelText' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3epar%3c/text%3e%3ctext x='883.5' y='412' text-anchor='middle' class='loopText' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3e%3ctspan x='883.5'%3e%5bgraph retrieval%5d%3c/tspan%3e%3c/text%3e%3ctext x='858.5' y='642' text-anchor='middle' class='sectionTitle' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3e%5bvector retrieval%5d%3c/text%3e%3c/g%3e%3cg class='actor-man actor-top' name='User' data-et='participant' data-type='actor' data-id='User' style='stroke: rgb(147%2c 112%2c 219)%3b'%3e%3cline id='actor-man-torso0' x1='75' y1='25' x2='75' y2='45'/%3e%3cline id='actor-man-arms0' x1='57' y1='33' x2='93' y2='33'/%3e%3cline x1='57' y1='60' x2='75' y2='45'/%3e%3cline x1='75' y1='45' x2='91' y2='60'/%3e%3ccircle cx='75' cy='10' r='15' width='150' height='65'/%3e%3ctext x='75' y='67.5' dominant-baseline='central' alignment-baseline='central' class='actor actor-man' style='text-anchor: middle%3b font-size: 16px%3b font-weight: 400%3b font-family: arial%2c sans-serif%3b'%3e%3ctspan x='75' dy='0'%3eUser%3c/tspan%3e%3c/text%3e%3c/g%3e%3ctext x='174' y='80' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3equestion%3c/text%3e%3cline x1='76' y1='109' x2='271' y2='109' class='messageLine0' data-et='message' data-id='i0' data-from='User' data-to='UI' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='fill: none%3b'/%3e%3ctext x='389' y='124' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3equestion %2b chat history%3c/text%3e%3cline x1='276' y1='153' x2='502' y2='153' class='messageLine0' data-et='message' data-id='i1' data-from='UI' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='fill: none%3b'/%3e%3ctext x='657' y='213' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3econdense to standalone question%3c/text%3e%3cline x1='507' y1='242' x2='807' y2='242' class='messageLine0' data-et='message' data-id='i3' data-from='App' data-to='Sm' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='fill: none%3b'/%3e%3ctext x='660' y='257' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3econdensed question%3c/text%3e%3cline x1='810' y1='286' x2='510' y2='286' class='messageLine1' data-et='message' data-id='i4' data-from='Sm' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='657' y='311' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eextract entity names%3c/text%3e%3cline x1='507' y1='340' x2='807' y2='340' class='messageLine0' data-et='message' data-id='i6' data-from='App' data-to='Sm' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='fill: none%3b'/%3e%3ctext x='660' y='355' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eentity list%3c/text%3e%3cline x1='810' y1='384' x2='510' y2='384' class='messageLine1' data-et='message' data-id='i7' data-from='Sm' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='757' y='444' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3efulltext query on blip_name index%3c/text%3e%3cline x1='507' y1='475' x2='1007' y2='475' class='messageLine0' data-et='message' data-id='i9' data-from='App' data-to='G' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='fill: none%3b'/%3e%3ctext x='760' y='490' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eblips %2b ring %2b tags %2b semantic edges%3c/text%3e%3cline x1='1010' y1='519' x2='510' y2='519' class='messageLine1' data-et='message' data-id='i10' data-from='G' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='757' y='534' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3efulltext query on tech_name index%3c/text%3e%3cline x1='507' y1='565' x2='1007' y2='565' class='messageLine0' data-et='message' data-id='i11' data-from='App' data-to='G' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='fill: none%3b'/%3e%3ctext x='760' y='580' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3etechnology usages by blip and ring%3c/text%3e%3cline x1='1010' y1='609' x2='510' y2='609' class='messageLine1' data-et='message' data-id='i12' data-from='G' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='857' y='669' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eembed %2b query top-4 chunks%3c/text%3e%3cline x1='507' y1='698' x2='1207' y2='698' class='messageLine0' data-et='message' data-id='i14' data-from='App' data-to='V' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='fill: none%3b'/%3e%3ctext x='860' y='713' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3esemantic chunks with metadata%3c/text%3e%3cline x1='1210' y1='742' x2='510' y2='742' class='messageLine1' data-et='message' data-id='i15' data-from='V' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='957' y='767' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3ecombined context %2b question%3c/text%3e%3cline x1='507' y1='796' x2='1407' y2='796' class='messageLine0' data-et='message' data-id='i17' data-from='App' data-to='Lg' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='fill: none%3b'/%3e%3ctext x='960' y='811' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eanswer stream%3c/text%3e%3cline x1='1410' y1='840' x2='510' y2='840' class='messageLine1' data-et='message' data-id='i18' data-from='Lg' data-to='App' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='392' y='855' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3estreamed tokens%3c/text%3e%3cline x1='505' y1='884' x2='279' y2='884' class='messageLine1' data-et='message' data-id='i19' data-from='App' data-to='UI' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3ctext x='177' y='899' text-anchor='middle' dominant-baseline='middle' alignment-baseline='middle' class='messageText' dy='1em' style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b'%3eresponse%3c/text%3e%3cline x1='274' y1='928' x2='79' y2='928' class='messageLine1' data-et='message' data-id='i20' data-from='UI' data-to='User' stroke-width='2' stroke='none' marker-end='url(%23mermaid-3-arrowhead)' style='stroke-dasharray: 3%2c 3%3b fill: none%3b'/%3e%3cg class='actor-man actor-bottom' name='User' style='stroke: rgb(147%2c 112%2c 219)%3b'%3e%3cline id='actor-man-torso6' x1='75' y1='973' x2='75' y2='993'/%3e%3cline id='actor-man-arms6' x1='57' y1='981' x2='93' y2='981'/%3e%3cline x1='57' y1='1008' x2='75' y2='993'/%3e%3cline x1='75' y1='993' x2='91' y2='1008'/%3e%3ccircle cx='75' cy='958' r='15' width='150' height='65'/%3e%3ctext x='75' y='1015.5' dominant-baseline='central' alignment-baseline='central' class='actor actor-man' style='text-anchor: middle%3b font-size: 16px%3b font-weight: 400%3b font-family: arial%2c sans-serif%3b'%3e%3ctspan x='75' dy='0'%3eUser%3c/tspan%3e%3c/text%3e%3c/g%3e%3c/svg%3e)
The graph retriever starts by asking llm_small to extract entity names from the question using structured output:
class Entities(BaseModel):
names: List[str] = Field(
description="Technology tools, frameworks, languages, practices, or platforms "
"mentioned in the text"
)
entity_chain = _entity_prompt | llm_small.with_structured_output(Entities)
For each entity name, the retriever builds a fuzzy Lucene query and hits two Neo4j fulltext indexes. The fuzzy matching handles abbreviations and near-typos:
def _generate_fulltext_query(text: str) -> str:
words = [w for w in remove_lucene_chars(text).split() if w]
return " AND ".join(f"{w}~2" for w in words)
The ~2 suffix tells Lucene to allow edit distance 2 per word. remove_lucene_chars strips characters Lucene treats as operators, preventing query injection. Two indexes get queried: blip_name (on Blip.name and Blip.shortSummary) returns ring, quadrant, domain tags, and semantic edge traversals in a single Cypher call. tech_name (on Technology.name) returns which blips reference a given technology and at which ring.
The vector retriever embeds the question and queries Qdrant for the four nearest chunks. Each point's payload includes blipName, ring, quadrant, and text, so the formatted result carries provenance alongside the chunk text rather than returning raw text.
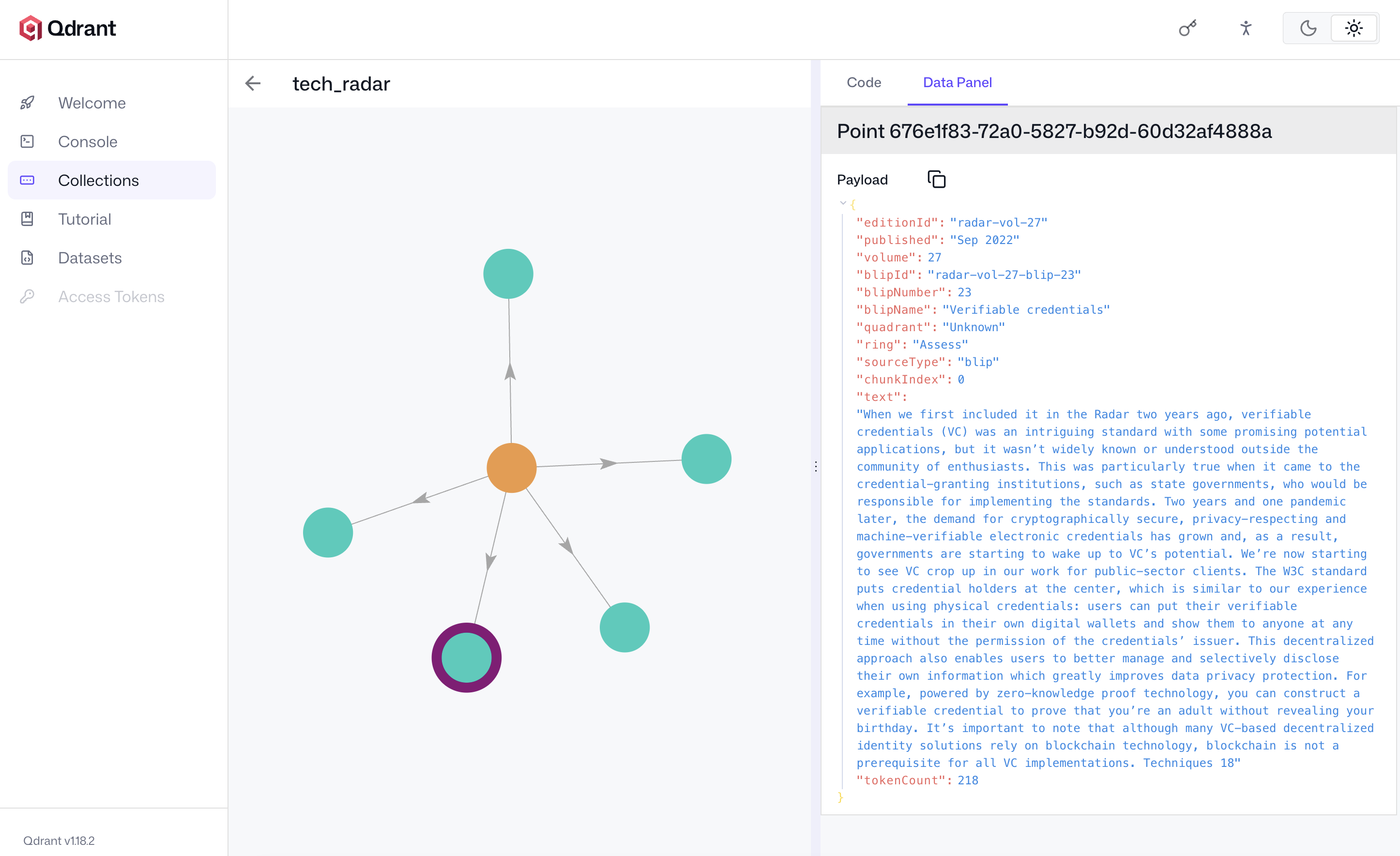
Chat history is handled by a RunnableBranch. When history is present, llm_small condenses it and the follow-up question into a standalone question before retrieval runs. When there is no history, the question passes through unchanged. The large model always handles the final answer:
_search_query = RunnableBranch(
(
RunnableLambda(lambda x: bool(x.get("chat_history"))),
RunnablePassthrough.assign(
chat_history=lambda x: _format_chat_history(x["chat_history"])
)
| CONDENSE_QUESTION_PROMPT
| llm_small
| StrOutputParser(),
),
RunnableLambda(lambda x: x["question"]),
)
chain = (
RunnableParallel({"context": _search_query | retriever, "question": RunnablePassthrough()})
| answer_prompt
| llm
| StrOutputParser()
)
The two-tier LLM split is an intentional cost/quality trade-off. llm_small handles entity extraction and question condensation, tasks where a smaller model is more than sufficient and where cost accumulates across many queries. llm handles the final answer where reasoning quality and grounding matter.
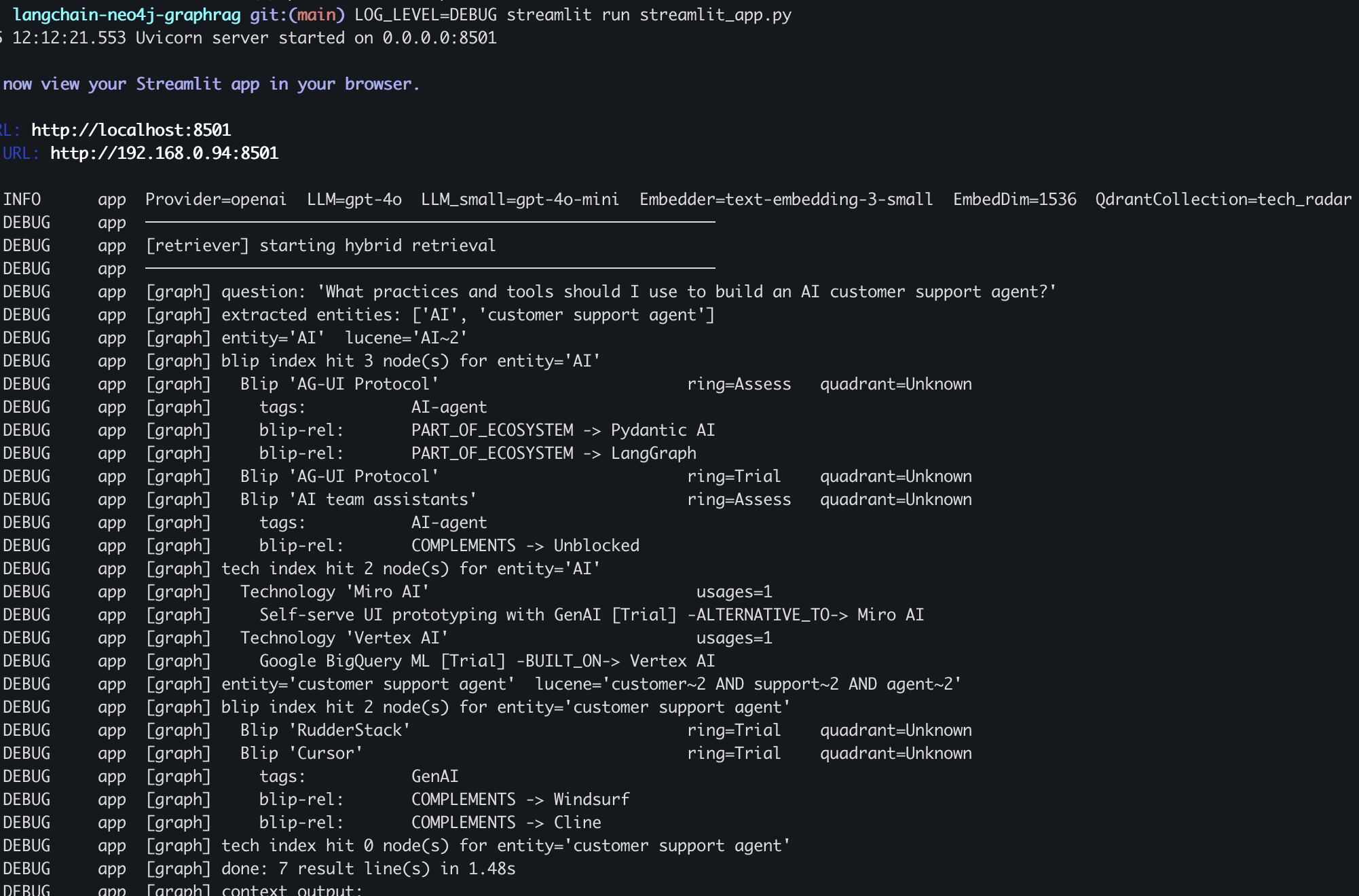
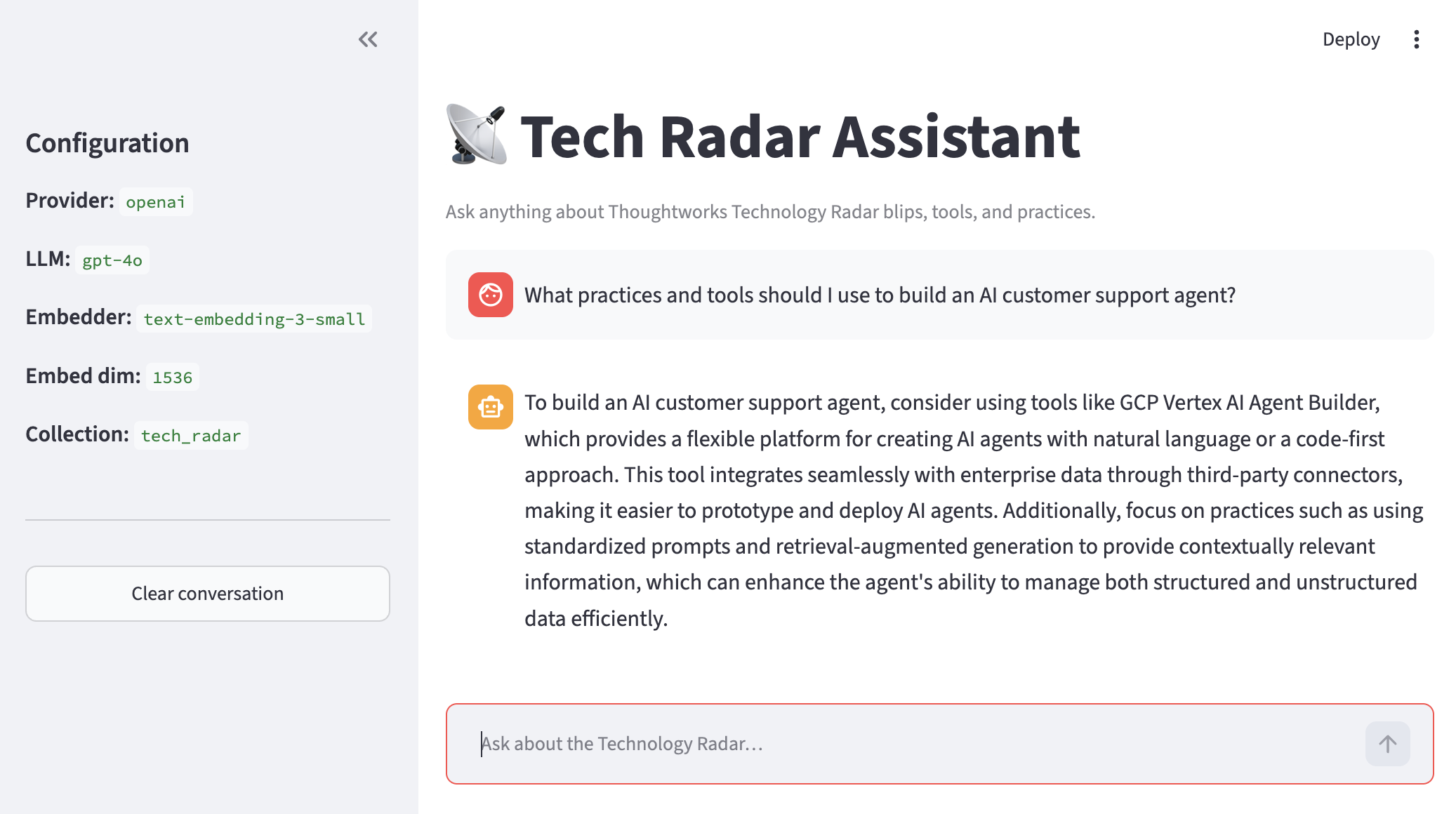
Knowing what you don't know
Every stage accepts an optional UnknownCollector instance. When the parser encounters ambiguous data (a blip with no detectable ring, a theme name that doesn't match any known themes, a blip reference from Stage 4 that Stage 5 can't resolve), it calls collector.record(stage, event_type, **details). The collector buffers records in memory and flushes them as newline-delimited JSON to pipeline_unknowns.jsonl at the end of processing each PDF, even if the pipeline fails partway through.
class UnknownCollector:
def record(self, stage: int, kind: str, **details: Any) -> None:
self._records.append({
"timestamp": datetime.now(timezone.utc).isoformat(),
"pdf_file": self._pdf_file,
"stage": stage,
"type": kind,
**details,
})
def flush(self) -> None:
if not self._records:
return
with UNKNOWNS_FILE.open("a", encoding="utf-8") as fh:
fh.write("\n".join(json.dumps(r) for r in self._records) + "\n")
Across 34 PDFs, the log captures every case where the pipeline fell back to placeholder data, every unresolved blip name reference, every ring inference the validator rejected. It gives a complete data quality audit without interrupting the pipeline. Querying it afterward shows exactly how much of the early-edition data is inferred versus parsed from source.
What actually worked
The best decision I made was parsing structural facts deterministically and using the LLM only for semantic extraction. Blip number, name, ring, quadrant: these are printed in the PDF. Using a language model to extract them would cost tokens, add retry complexity, and introduce hallucination risk for information that regex handles without ambiguity. The LLM's job is extracting things that are not expressed as structured data: relationship types between blips, external technology mentions, domain tags, and ring values for early editions where the ring isn't stated per blip.
Pydantic Literal types for the LLM's output vocabulary mattered more than I expected. The first version of BlipSemantics used plain str for relationship types, and the model reliably generated "USES", "DEPENDS_ON", "COMPATIBLE_WITH": syntactically valid strings, but none of them match any Neo4j edge type. Switching to BlipRelType = Literal["COMPLEMENTS", "REFERENCES", ...] fixed the problem entirely. The structured output schema doubles as a constraint that the model sees and respects.
PDF parsing across 15 years of format changes is harder than it looks. I expected two layout variations; I found three distinct formats and multiple sub-variations within each. The _EARLY_BLIP_RANGES hardcoded table is the ugliest code in the project. For a production data pipeline I would invest in a human-verified metadata dataset for the early editions. For this project, the fallback gets the job done.
Checkpointing at each stage changed how the pipeline behaves under failure. Before adding it, a network error during Stage 4 on edition 27 of 34 meant starting over from the beginning. After, the same interruption resumes from Stage 4 on edition 27. When I was iterating on Stage 5 fuzzy matching logic, I wiped just the Stage 5 checkpoint for all files and re-ran without touching the embedding or LLM extraction work. That kind of resumability is standard in production data pipelines. It doesn't arrive for free; it required explicit design here.
Hybrid retrieval performs noticeably better than either method alone, a finding HybridRAG (2024) confirms across different domains. The graph retriever catches precise entity relationships that vector search misses, particularly multi-hop queries. The vector retriever catches thematic similarity that fulltext graph queries miss, particularly when the user's question uses vocabulary that doesn't map directly to blip names. The final LLM model gets enough signal from the combined context for specific, grounded answers.
Running against local Ollama during development and OpenAI in production, through the same code path, worked well. Most development iteration happened against llama3.1:8b and nomic-embed-text on a homelab machine at zero API cost. The same pipeline code and query application work with OpenAI by setting LLM_PROVIDER=openai. The only code difference is embedding dimension (768 vs 1536), handled by a property on the Settings model.
If I were starting over, I would characterize all 34 PDFs up front before writing a single parsing function. I built the modern parser first, added intermediate support when I noticed wrong results on 2011–2013 editions, and handled early editions after four PDFs produced empty blip lists. A proper upfront survey would have surfaced all three format types before any code was written, and I would have designed the detection logic and fallback mechanisms from the beginning rather than retrofitting them.
Further reading
RAG and GraphRAG foundations
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks: Lewis et al. (2020), the paper that introduced RAG as a pattern for grounding LLM outputs in retrieved documents
- From Local to Global: A Graph RAG Approach to Query-Focused Summarization: Edge et al. (2024), Microsoft's GraphRAG using LLM-generated community summaries for global sensemaking over large corpora
- HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction: empirical comparison showing hybrid graph + vector retrieval outperforms either approach alone
Knowledge graph + LLM tooling
- Create a Neo4j GraphRAG Workflow Using LangChain and LangGraph: Neo4j's official guide combining graph queries, vector search, and LangGraph for agentic RAG workflows
- Enhancing RAG-based Application Accuracy by Constructing and Leveraging Knowledge Graphs: LangChain's introduction to their graph construction modules and how graph queries complement vector retrieval
PDF parsing
- A Comparative Study of PDF Parsing Tools Across Diverse Document Categories: October 2024 benchmark of PyPDF, PDFMiner, and others across scientific, financial, and general documents, with failure mode analysis
